こんにちは。開発本部 データウェアハウス開発部 データレイクグループの竹内です。
4月初旬にAmazon Web Service(以下、AWS)のRedshiftパフォーマンスチューニングワークショップに参加しました。
本ブログでは、ワークショップの内容についてご紹介いたします。
読者の皆様に、ワークショップの様子を少しでもお伝えできれば幸いです。
1. ワークショップ概要
目的:Redshiftの基本的な仕組みを理解し、実務で役立つクエリ高速化のポイントを学ぶこと
場所:AWS社 目黒オフィスでのオフライン開催(3時間)
参加者:弊社データウェアハウス開発部からエンジニア10名
2. 読んでほしい方
こんな方におすすめです。
* Redshiftのパフォーマンスチューニングに興味がある方
* 短時間で基礎を押さえたい初心者の方
* 一度学んだ内容を体系的におさらいしたい経験者の方
3. ワークショップの内容
3-1. Redshiftの仕組みを理解する
ここから、当日配布された資料から抜粋して内容についてお伝えしたいと思います。
前半は座学で、AWSのスペシャリストからRedshiftの基本アーキテクチャや処理の仕組みを学びました。

Redshift Serverlessはマネージドサービスなのでアーキテクチャはかなりざっくりしたものでした。
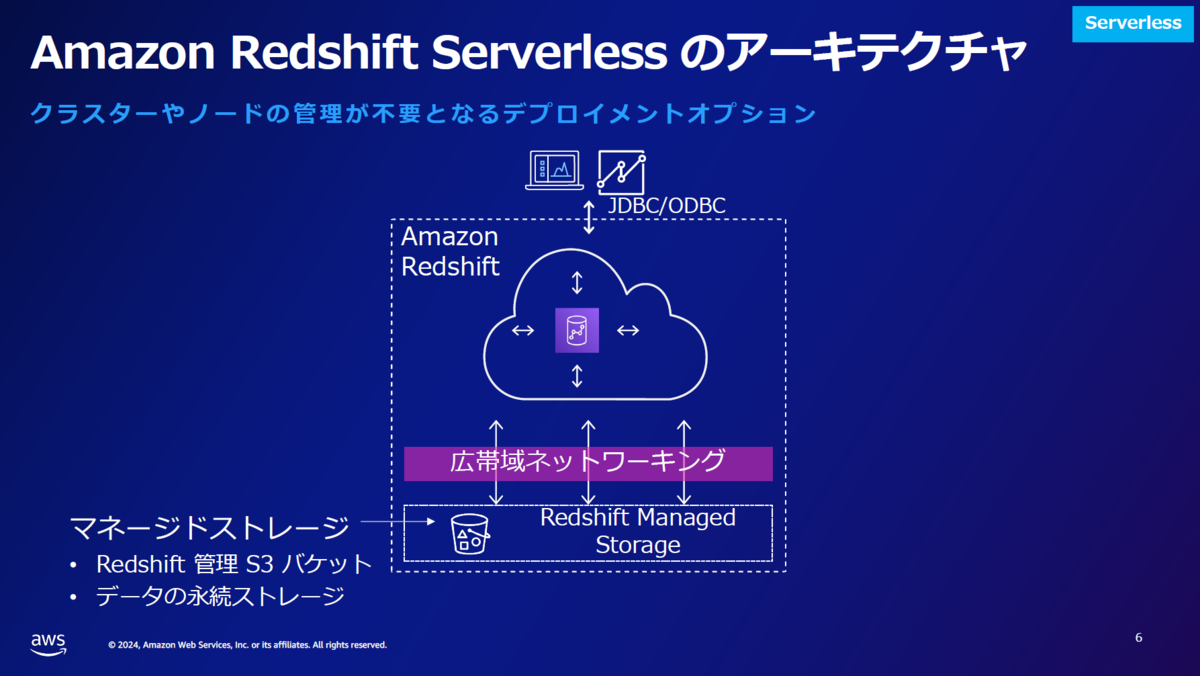
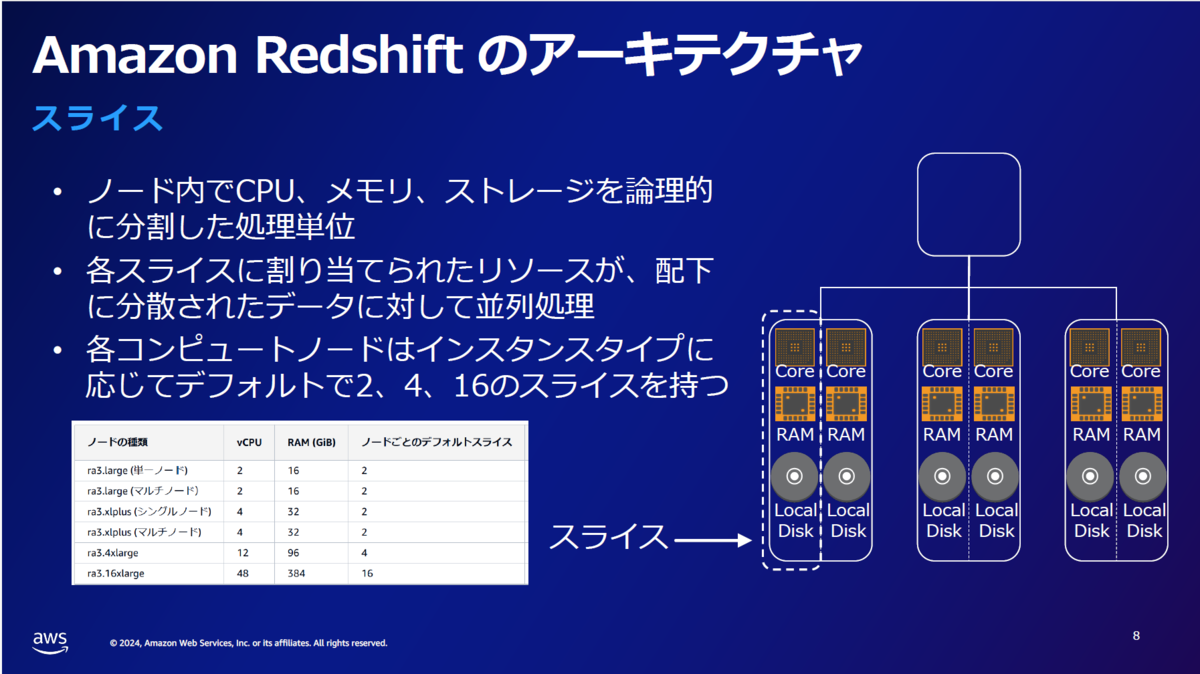
以下のスライスは、通常ユーザーが意識することはありませんが、
Redshiftは大量データを高速に処理するために、データを「スライス」と呼ばれる単位に分割し、複数の処理を並列で実行します。
これは、複数の作業を同時に行うことで、処理速度を向上させる仕組みと理解できます。
私はざっくり「とにかく速くできる仕組みを持っている!」と覚えることにしました。
Redshiftを高速化するためのポイントは、主に以下の2点です。
1. I/Oを削減すること
2. 効率的に並列処理を行うこと
具体的な解決策については、以下にご紹介します。
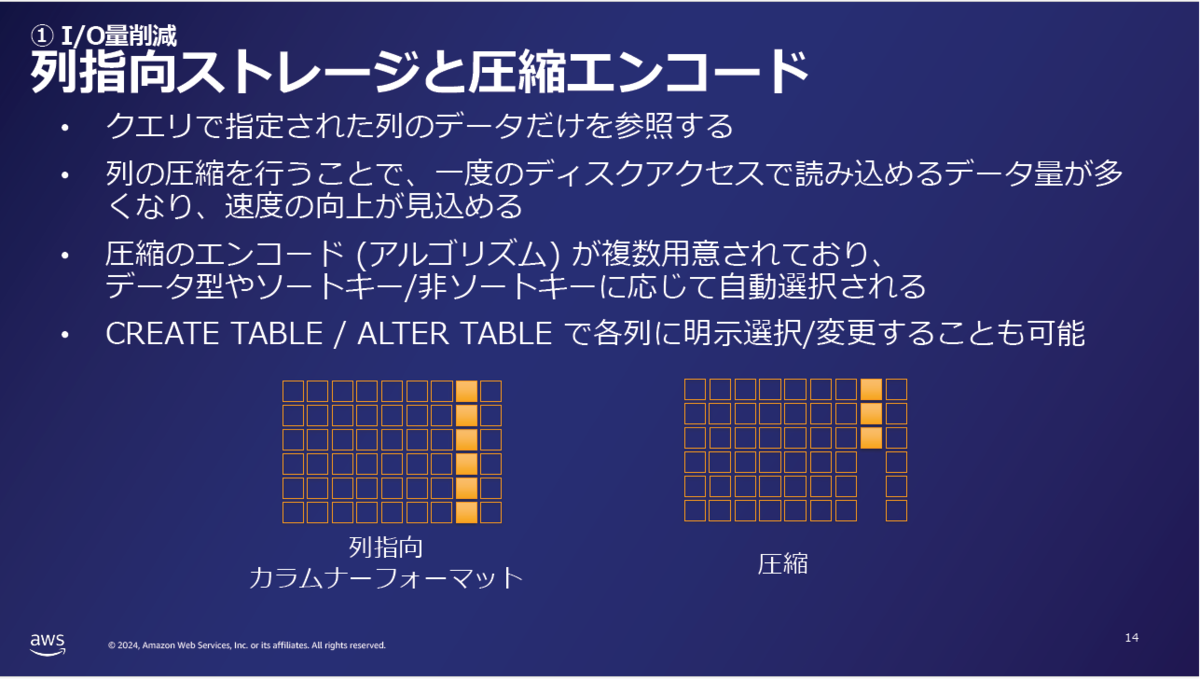
1. I/Oを減らす方法:ソートキーの設定、圧縮エンコードの使用
圧縮エンコードについては以下のスライドに詳しい説明が載っています。
簡単に言うと、列ごとにデータを圧縮できる仕組みです。
例えば売上明細などのトランザクション系のテーブルだと、「○○支店」といった名称項目は同じ値が複数行に存在するので、この機能を使うと最適に圧縮してくれます。
ソートキーがなぜ速くなるのか?それは以下のスライドがわかりやすいです。
このスライドの例は数値ですが、私は期間で考えるとさらにわかりやすいと思いました。
例えば直近1年の売上データを抽出するクエリで考えると、日付が順番に並んで保存されていれば検索範囲が絞られて余分なI/Oを減らせるので、ソートキーが有効といえます。

ただし、選び方には注意事項があるので、ご検討の際にはこちらのスライドを参考にしてください。
また、INSERTの時に並び替えながらデータを登録するようになるので、INSERTのパフォーマンスに影響がないかどうかも検証したうえでソートキーを設定することをおすすめします。

ソートキーについて補足です。
複数キーを設定する場合、設定したソートキーの順番とWhere句で記述する順番は同じである必要はありません。
参加者からの質問からわかった内容で、資料には載っていないため、こちらも共有したいと思います。
2. 効率的に並列で処理をさせる方法:分散スタイルと分散キーの設定
Redshiftで「分散させる」とは、「各スライスにバランスよくデータを分割して並列処理をさせる」ということです。
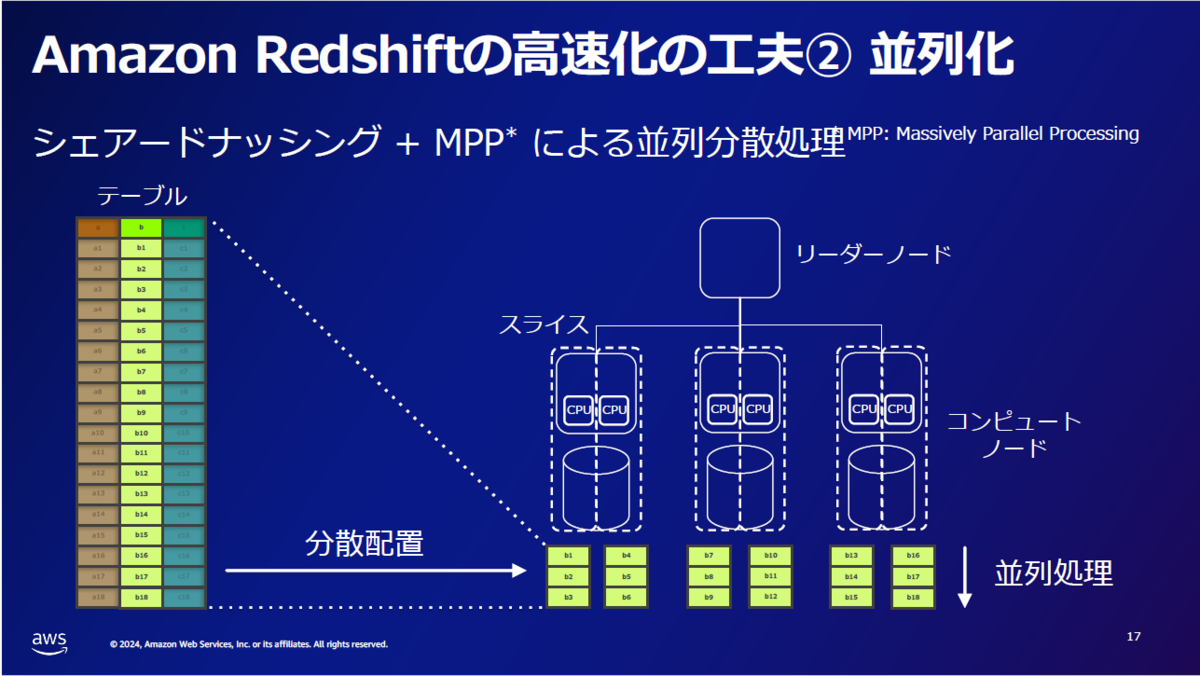
しかし分散スタイルの決め方にも注意が必要です。例えばテーブルをJOINする場合は同じキー値のデータが違うノードに散らばっているよりも同じノードにあった方がI/Oが減るため速いです。
データ量が少なく、処理全体で参照されるような管理系テーブルは下図真中の「ALL」で全ノードにデータを持たせると良いと思います。
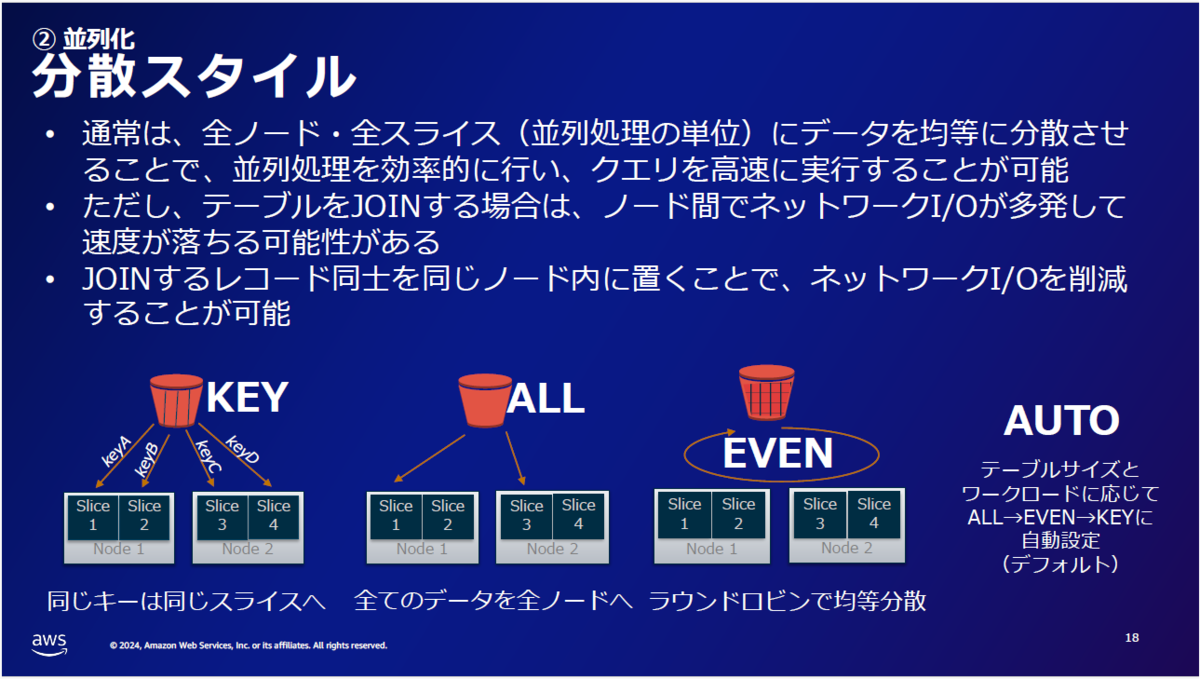
各分散スタイルを採用する主なケースも紹介がありました。


3-2. ボトルネック分析の方法について学ぶ
さて、Redshiftについて少し詳しくなったところで、次はボトルネック分析の手法について学びました。
参加者からは、「説明が分かりやすかった!」という声が多く、Redshiftを初めて利用するメンバーからも好評でした。
パフォーマンス改善の第一歩は、「どこに時間がかかっているかを特定すること」。
「その分析方法がよくわからない」と思ったみなさんに、こちらのスライドを共有します。
以下のように、手順が体系的になっています。
こうやって筋道が立てられていると、やることが明確でわかりやすいですね。

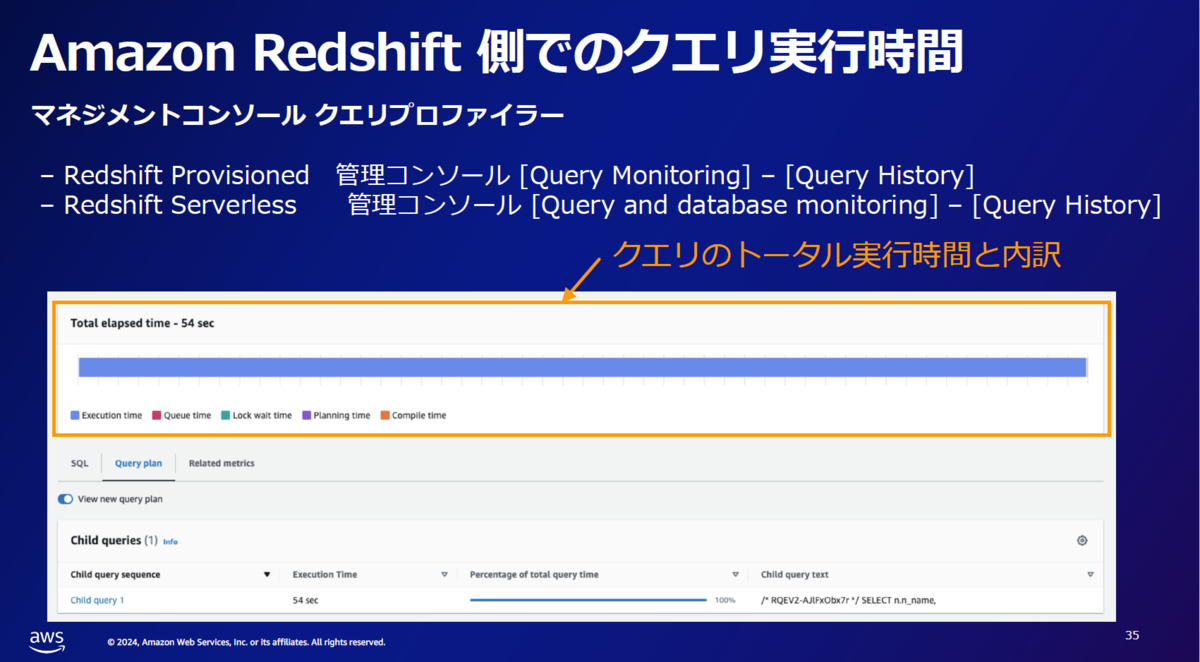
パフォーマンスを確認するにはマネジメントコンソールとシステムビューを使います。
Serverlessの場合、Provisionedと比較すると使用できるシステムビューが少ない(一部のSVVビューとSYSモニタリングビューが使用可能)ですが、クエリチューニングについての調査は十分できます。
クエリのボトルネックを分析する時に役立つ俯瞰図もわかりやすいと感じたので、こちらも紹介します。

docs.aws.amazon.com
docs.aws.amazon.com
docs.aws.amazon.com
より分かりやすい調査方法として、AWSが新たに提供したクエリプロファイラーがあります。
この機能は、長時間実行されているクエリを分解し、ボトルネックとなっている箇所を視覚的に表示します。
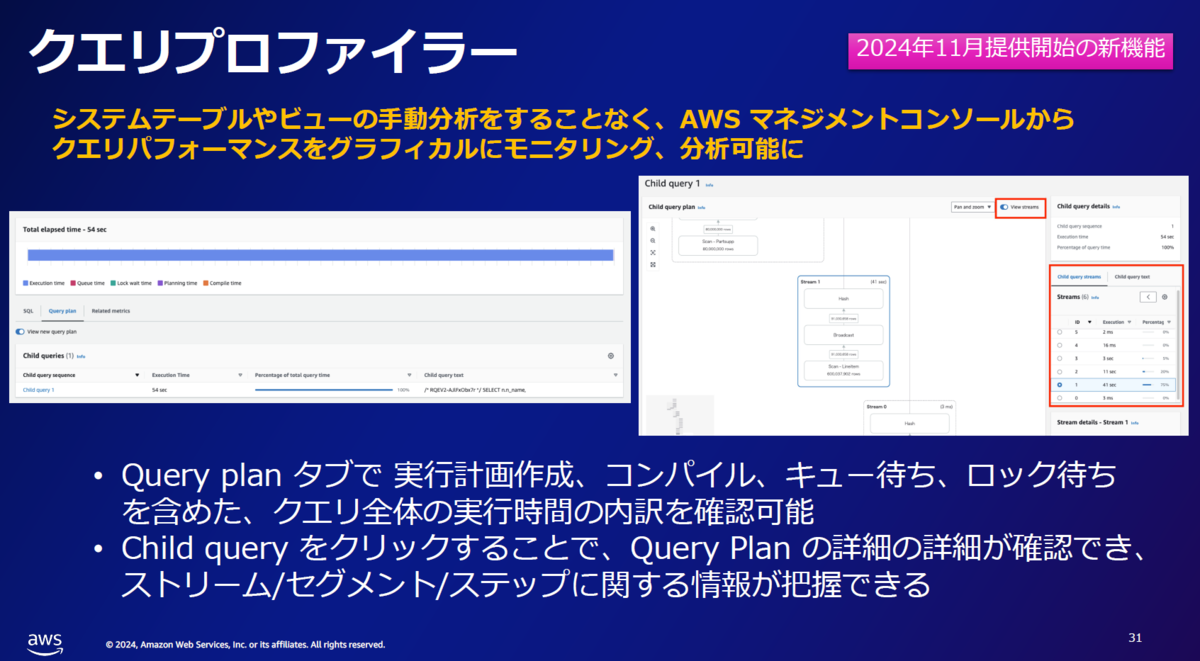
この後のハンズオンでもこの機能を使ってボトルネックを探しました。
参加者全員とても感動していて、「これは実務でも早速使える。みんなに教えたい!」ととてもポジティブな声が出ていました。
使い方は以下の資料が参考になります。
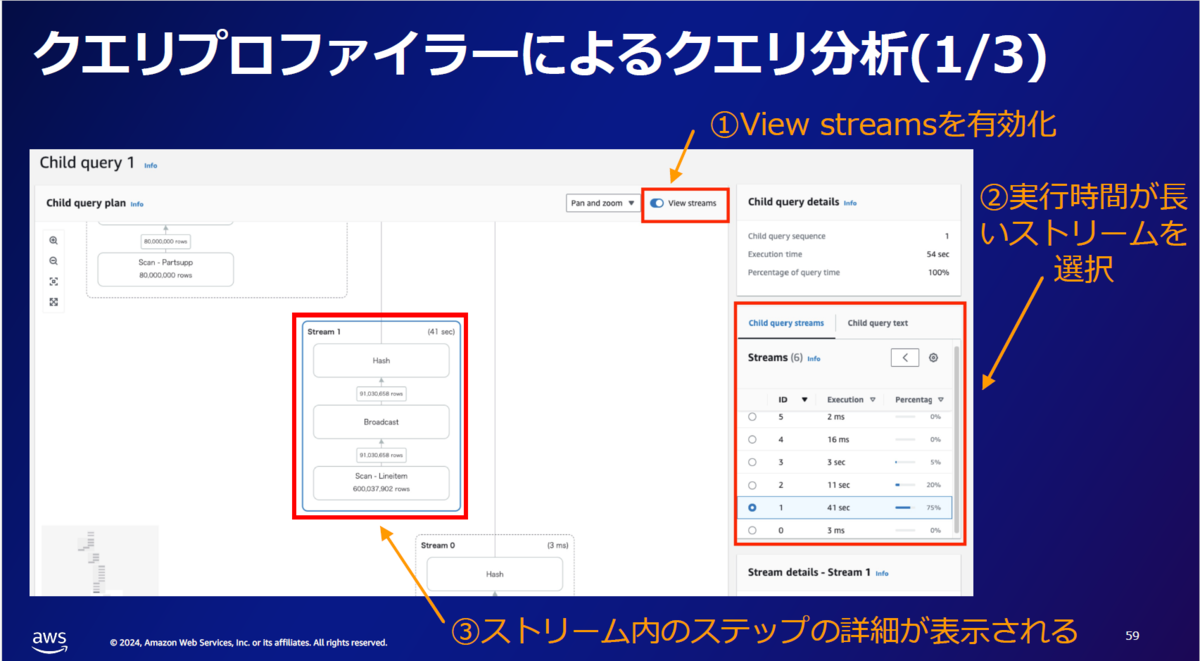


座学の最後に、結合に関する確認ポイントがまとまったスライドもありましたので、こちらも紹介します。

3-3. いよいよハンズオン
座学の後は、お待ちかねのハンズオンです!私たちが実際に解いた問題はこちらのリンクから確認することができます。
catalog.us-east-1.prod.workshops.aws
私たちはワークショップ用の一時的な環境を作っていただき、そこで操作しました。オブジェクトも用意されています。
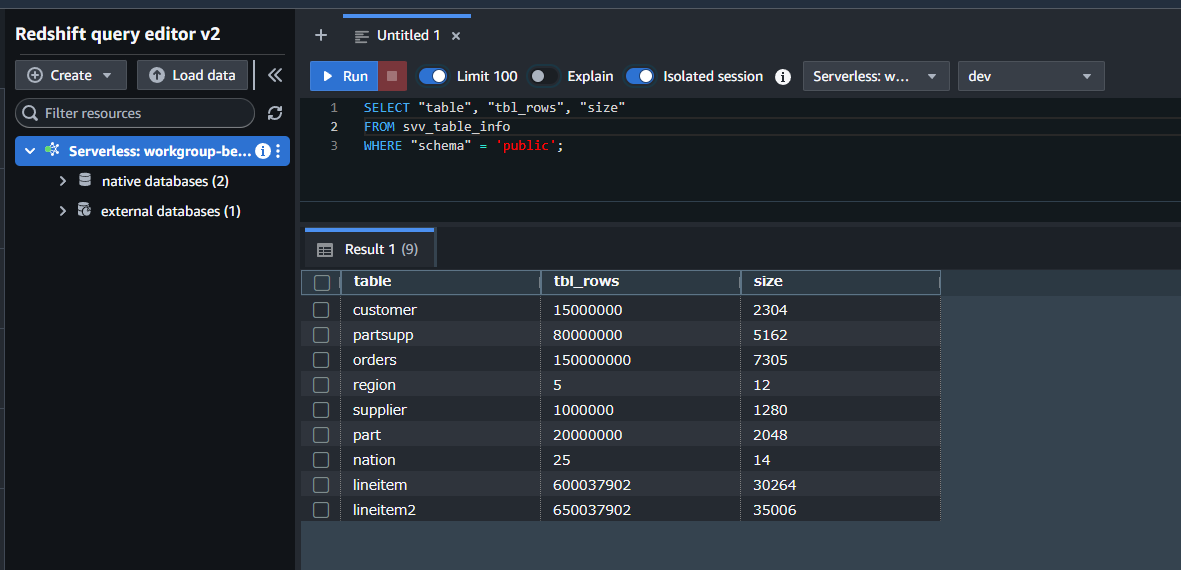
全3問ですが、時間の都合上、クイズは2問目まで実施しました。回答時間は15分、解説15分のペースです。
「実際に使ってらっしゃる方はヒントを見ないで自力でやってみましょう。」という言葉に若干のプレッシャーを感じながら、1問目に取り掛かります。
直前のセッションでしっかり学んだこともあり、参加者全員が全問正解!・・・とはなりませんでした。
実は1問目は全員時間切れでした。
実際にやってみたところ、問題文を読んだ後に、「どういう手順で分析するんだったかな?」とまず慌ててしまいます。
そして、配布されたPDFを見ながら手を動かします。
問題文を理解しつつ、教わった手順を実際にやってみる。この2つを同時にやると15分はとても短く感じました。
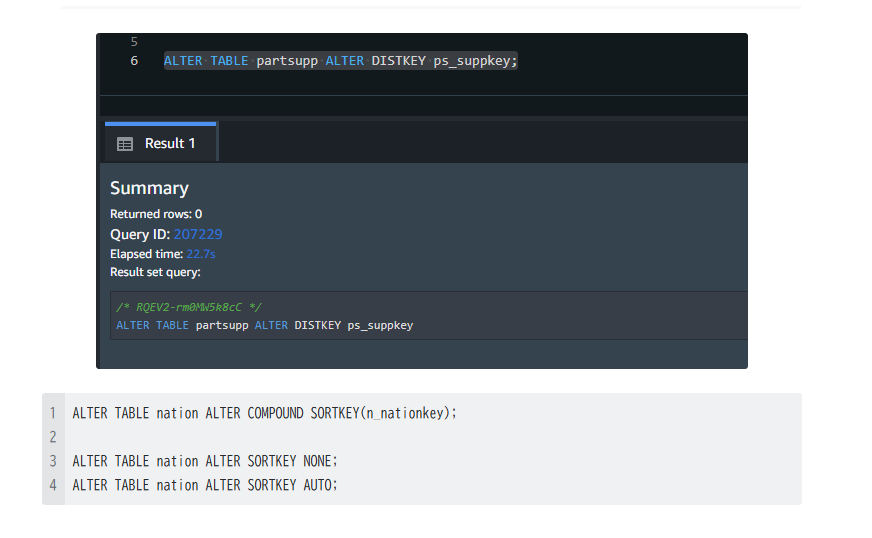
私は違うテーブルに分散キーを追加してしまい、当然ながら、クエリのパフォーマンスは改善されませんでした。
座学で理解した内容を、実際に適用することの難しさを痛感しました。
下の画面は私の間違った分散キーを設定したところを切り取っています。
クイズが不正解だったため「私も分散してしまいたいな」と一瞬思いましたが、この失敗も学びの一環と気持ちを切り替えました。
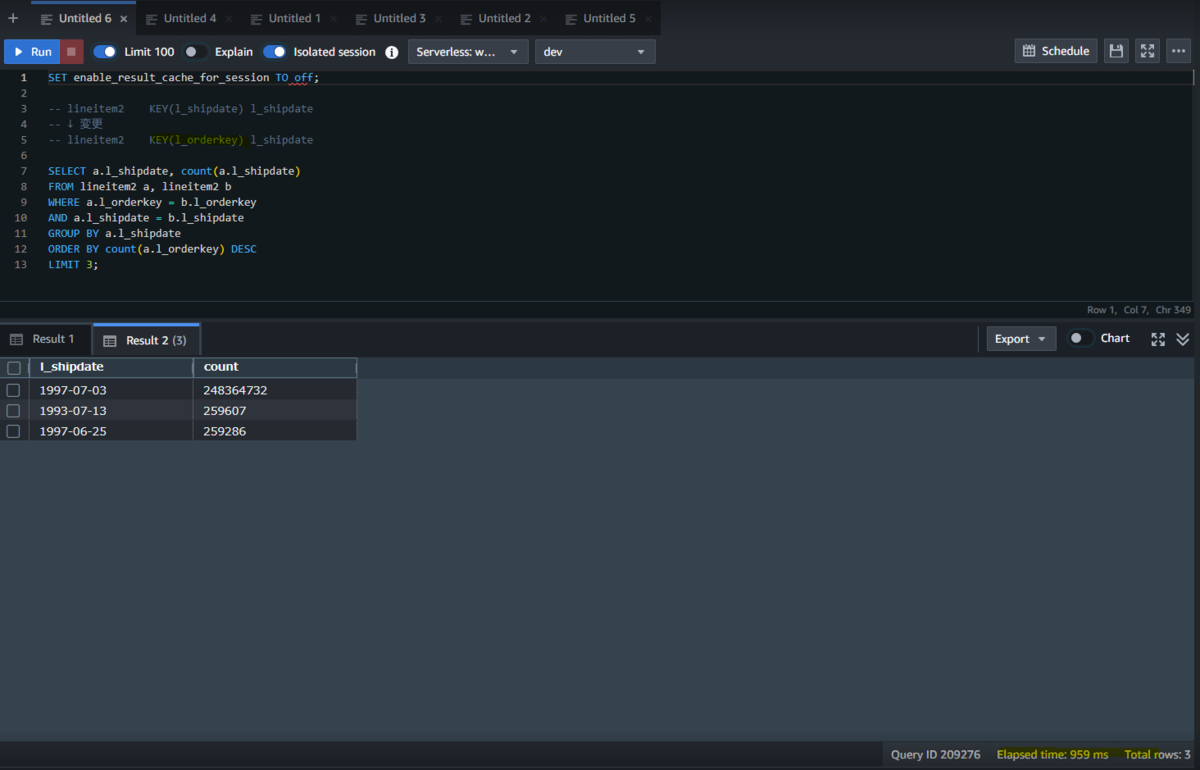
続く2問目はほとんどの参加者が正解を出しており、みなさん1問目でコツを掴んだことがわかりました。
わたしも解けたことがうれしく、クエリの実行時間が速くなった画面をスクショしてしまいました。
やればできる!
2問クイズを解いただけですがやり応えがありました。残りのクイズは後日各々が解くことになり、ワークショップは終了となりました。
4. 今回の学び・気づき
- Redshiftの基本から実践的なチューニング方法まで幅広く学べました
- 経験者も基礎に立ち返る良い機会になりました
- クエリプロファイラーは特に高評価で、実務での活用が期待されます
5. 実務での次のステップ
ここは参加者のみなさんの声を載せたいと思います。
- ちょうどAWS移行に向けてテーブル設計中なので、圧縮エンコードを最適化したい(Y.Fさん)
- 今後、性能問題がわかったPJ/シーンでは今回の資料を展開したい(H.Oさん)
- 既存オブジェクトのソートキーを見直したい(T.Kさん)
- 運用SQLのチューニングに今回の分析方法を使用したい(K.Yさん)
- チューニングに使えるシステムビューを活用していきたい(K.H.さん)
6. 実務に組み込む場合の注意点
ワークショップのクイズは特定のクエリに対してパフォーマンスを改善してみるという形でしたが、
複雑な実際の現場では全体を俯瞰して考える必要があります。
ワークショップ中、講師の方から
「複雑なSQLではソートキーの効果が薄れる場合や、分散キーの設定時に複数のクエリで利用されるキーを考慮する必要があるなど、現実は単純ではない」という注意点がありました。
おっしゃる通りです。
実際には「このクエリは速くなったが、他のクエリが遅くなった」といったことが起きないよう、システムの処理の流れを理解していることが前提条件です。
「ローマは1日にしてならず」。各システム担当者が責任をもって地道にパフォーマンス改善に取り組んでいきたいと思います。
7. 総括
部門内のエンジニアの力試しと知識底上げの場として最適なワークショップでした。
同じような環境の方にはぜひ参加をおすすめします!
会社のメンバーを誘って、みんなでワークショップに参加してみてはいかがでしょうか。
