初めまして!株式会社JMDC データウェアハウス開発部 データレイクグループの後藤です。
今年、JMDCではアドベントカレンダーに参加しています。
本記事は、JMDC Advent Calendar 2024 13日目の記事です。
データレイクグループでは、JMDCが保有する多数のデータを分析する際の軸として必要なマスタデータ(以下、マスタ)の開発・運用・保守を行っています。
各サービスのニーズに合わせて多種のデータソースを利用しているため、多くのマスタを取り扱っています。
少し古いですが、データレイクグループの雰囲気がわかりますので興味がある方は下記記事も読んでみてください!
今回は業務で行った事例を紹介いたします。
Oracle Data Pumpとシェル(+いくつかのSQL)を利用して、本番からテストへのデータ移行ツールを作成してみたという内容になります。
目次
きっかけ
弊社には別グループに業務アプリケーションを用いてマスタをメンテナンスするチームが存在します。
メンテナンスチームから以下のような要望がありました
- データソースに特殊なパターンのデータが出てきた時にテスト環境で検証を素早く行いたい
- メンテナンス担当者ローテーションのためのトレーニングを行いたいので、定期的に本番レベルのデータをテスト環境に用意したい
- これらをマスタ毎に行いたい
こうした要望に対応するため、マスタ毎に本番データをテスト環境に復元する仕組みを模索・用意する必要がありました。
Oracle Data Pumpについて
簡単にデータを移行・復元ができるツールが無いかと思って調べていたところ、OracleにはOracle Data Pumpという機能が存在することを知りました。
Oracle Data PumpはOracleのデータのエクスポート・インポートを効率的に行うツールです。
データをエクスポートするにはexpdpを使い、インポートするにはimpdpを使用します。
この機能は予めディレクトリオブジェクトを作成しておく必要があります。
ディレクトリオブジェクトを設定する手順については、公式ドキュメントを参照してください。
【CREATE DIRECTORYコマンド】CREATE DIRECTORY
expdp
- その時点のスキーマ・テーブルをダンプファイルとしてエクスポートが可能
- excludeオプションで特定の名前で除外してエクスポートすることが可能
impdp
- エクスポートしたダンプファイルをインポートする。テーブルのみのインポートや、ビューやシーケンス等も丸ごとインポート可能
- Includeオプションで特定の名前でフィルタリングしてインポート可能
詳しくは公式のヘルプを読んでみてください。
【公式ヘルプ】Oracle Data Pump
Oracle Data Pump活用の検討
impdpのIncludeオプションを使えば、マスタ名でフィルタしたテーブルのみインポートできるので、
簡単にできるのでは?と思い、データ移行を行ってみたところ
*テーブルのインポートされる順番を指定できないため、外部キー制約に引っかかる可能性がある
* シーケンスが既存と重複するとエラーが発生する
ということが判明し、問題なく作業を行うには
- expdpを利用して本番スキーマからエクスポート
- インポートするテストスキーマの外部キーを無効化
- テストスキーマのシーケンスを削除
- impdpを利用してテストスキーマに特定のマスタに該当するテーブル・シーケンスをインポート
- テストスキーマの外部キーを有効化
- テストスキーマのオブジェクトにコンパイルエラーがいないか確認
と、まあまあ手間になりました。
1回だけの手動ならこれでもいいかなと思うのですが、データ移行の対応は頻繁に発生します。
また、それに伴うオペミスも怖いなと思っていたので、チーム内で相談した所、
いっそのこと作業内容を自動化してしまえば、オペミスを防ぎつつ開発チーム内のデータ移行ツールとしても使えるのでは?と意見が出たのでやってみることにしました。
ツール化するために行ったこと
環境
サーバー
RHEL
DB
OracleDB
スクリプト化する作業
- expdpを利用して本番スキーマからエクスポート
- インポートするテストスキーマの外部キーを無効化
- テストスキーマのシーケンスを削除
- impdpを利用してテストスキーマに特定のマスタに該当するテーブル・シーケンスをインポート
- テストスキーマの外部キーを有効化
- テストスキーマのオブジェクトにコンパイルエラーがいないか確認
2~6は全てインポートで行う作業です。
この内容をシェルでスクリプト化することにしました。
実装
シェルの構成ですが、
テーブルとシーケンスインポートを同時には行いたくないので、3段階に分けます。
- メインシェル
- テーブルをインポートするシェル
- シーケンスをインポートするシェル
メインを起動すると2・3が呼び出される作りにします
次に外部キーの制御とシーケンスの削除処理ですが、シェルからでは難しいので
SQLを作成し、それぞれのインポートの際に呼び出すようにします。
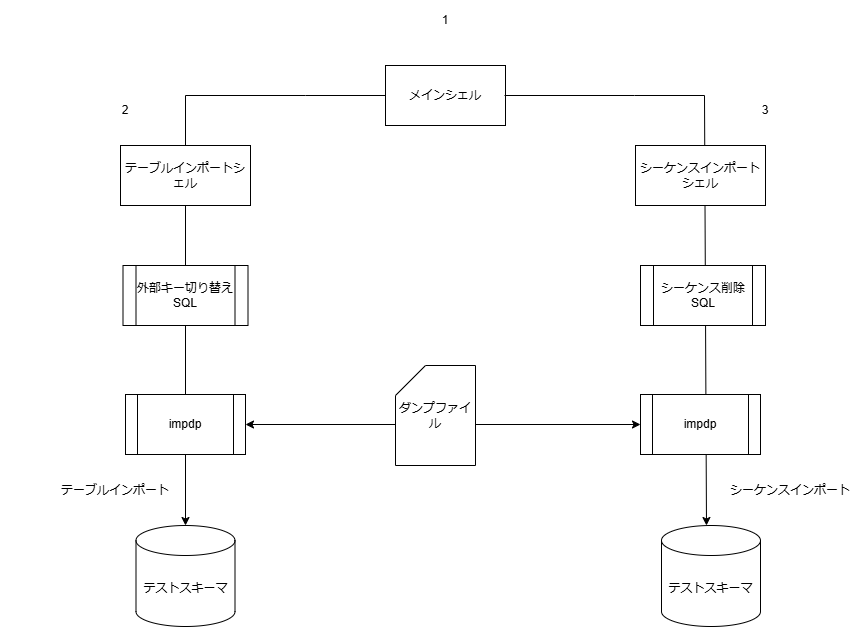
次からサンプルコードを紹介していきます。
シェル
1. メインシェル
起動用のシェルです。
OracleDataPumpがディレクトリオブジェクトを使用する機能のため、ダンプファイルが所定のディレクトリ内に存在している前提で実行します。
サンプルコード表示
#Impdp_ex.sh #------------------------------------------------------------------------------ # 引数定義 #------------------------------------------------------------------------------ # 対象環境 target_env="${1:?}" # フィルタリングするテーブル名 target_filter_name="${2:?}" # インポートするダンプファイル名 imp_dmp_file="${3:?}" #------------------------------------------------------------------------------ # 定数定義(固定) #------------------------------------------------------------------------------ # インポート先サーバーのsysのパスワード sys_pass="*******" # スキーマ間でやり取りしない前提で固定にする # インポート元スキーマ名 target_schema_from="test" # インポート先スキーマ名 target_schema_to="-test" # ダンプ入出力用 Oracleディレクトリオブジェクト dir_obj="DATA_PUMP_DIR" #------------------------------------------------------------------------------ # インポート実行 #------------------------------------------------------------------------------ # テーブルインポートシェル呼び出し exec_cmd="sh impdp_table.sh ${sys_pass} ${dir_obj} ${target_env} ${target_schema_from} ${target_schema_to} ${target_schema_to} ${target_filter_name} ${imp_dmp_file}" echo "[`date '+%F %T'`] テーブルのみインポート開始:${exec_cmd}" eval "${exec_cmd}" echo "[`date '+%F %T'`] テーブルのみインポート終了" echo "" # シーケンスインポートシェル呼び出し exec_cmd="sh impdp_sequence.sh ${sys_pass} ${dir_obj} ${target_env} ${target_schema_from} ${target_schema_to} ${target_schema_to} ${target_filter_name} ${imp_dmp_file}" echo "[`date '+%F %T'`] シーケンスのみインポート開始:${exec_cmd}" eval "${exec_cmd}" echo "[`date '+%F %T'`] シーケンスのみインポート終了"
2. テーブルをインポートするシェル
impdpを呼び出してテーブルインポートを実行します。
インポート前後に、作成した外部キー制約を切り替えるsqlを呼び出しています。
最後にエラーオブジェクトの再コンパイルも行います。
サンプルコード表示
#impdp_table.sh #------------------------------------------------------------------------------ # 引数定義(メインから渡される) #------------------------------------------------------------------------------ # インポート先サーバーのsysのパスワード sys_pass="${1:?}" # ダンプ入出力用 Oracleディレクトリオブジェクト dir_obj="${2:?}" # ネットサービス名 oracle_tns="${3:?}" # インポート元スキーマ名 target_schema_from="${4:?}" # インポート先スキーマ名 target_schema_to="${5:?}" # インポート先スキーマのパスワード target_schema_to_pass="${6:?}" # フィルタリングするテーブル名 target_filter_name="${7:?}" # インポートするダンプファイル名 imp_dmp_file="${8:?}" #------------------------------------------------------------------------------ # インポート実行 #------------------------------------------------------------------------------ # 出力ログ log_file="log.log" # impdpコマンドの作成 exec_cmd="impdp \\\"sys/${sys_pass}@${oracle_tns} as sysdba\\\" \ DIRECTORY=${dir_obj} \ DUMPFILE=${imp_dmp_file} \ LOGFILE=${log_file} \ REMAP_SCHEMA=${target_schema_from}:${target_schema_to} \ TABLE_EXISTS_ACTION=TRUNCATE \ CONTENT=data_only \ INCLUDE=TABLE:\\\"IN\({target_filter_name}\)\\\"" echo "[`date '+%F %T'`] 実行内容:${exec_cmd}" echo "" read -p "上記内容でデータのみインポートします。よろしいですか? (y/n): " yn case "$yn" in [yY]*) ;; *) exit ;; esac echo "" # 外部制約キーを無効化 sqlplus -s -l "${target_schema_to}/${target_schema_to_pass}@${oracle_tns}" << EOS REM 外部キー切り替え EXEC IMPDP_SUB.SWITCH_FOREIGNKEY('n','${target_filter_name}'); # 作成した外部キー制約の切り替えSQL呼び出し EOS # 実行 echo "[`date '+%F %T'`] インポート開始" eval "${exec_cmd}" result_status=$? echo "[`date '+%F %T'`] インポート終了[終了ステータス=${result_status}]" echo "" # 外部制約キーを有効化 echo "[`date '+%F %T'`] 対象スキーマ(To)の外部キー制約を全有効化とエラーオブジェクトの再コンパイル 開始" sqlplus -s -l "${target_schema_to}/${target_schema_to_pass}@${oracle_tns}" << EOS REM 外部キー切り替え EXEC IMPDP_SUB.SWITCH_FOREIGNKEY('y','${target_filter_name}'); # 作成した外部キー制約の切り替えSQL呼び出し REM エラーオブジェクトの再コンパイル EXEC DBMS_UTILITY.COMPILE_SCHEMA('${target_schema_to}', FALSE); EOS echo "[`date '+%F %T'`] 対象スキーマ(To)の外部キー制約を全有効化とエラーオブジェクトの再コンパイル 終了"
3. シーケンスをインポートするシェル
impdpを呼び出してシーケンスインポートを実行します。
インポート前に作成したシーケンスを削除するsqlを呼び出しています。
サンプルコード表示
#impdp_sequence.sh #テーブルをインポートするシェルと同じ引数を宣言しているため引数を省略 # 出力ログ log_file="log.log" # impdpコマンドの作成 exec_cmd="impdp \\\"sys/${sys_pass}@${oracle_tns} as sysdba\\\" \ DIRECTORY=${dir_obj} \ DUMPFILE=${imp_dmp_file} \ LOGFILE=${log_file} \ REMAP_SCHEMA=${target_schema_from}:${target_schema_to} \ INCLUDE=SEQUENCE:\\\"IN\(${target_filter_name}\)\\\"" echo "[`date '+%F %T'`] 実行内容:${exec_cmd}" echo "" # 実行 read -p "上記内容でシーケンスのみインポートします。よろしいですか? (y/n): " yn case "$yn" in [yY]*) ;; *) exit ;; esac echo "" echo "[`date '+%F %T'`] スキーマ内シーケンス削除 開始" sqlplus -s -l "${target_schema_to}/${target_schema_to_pass}@${oracle_tns}" << EOS EXEC IMPDP_SUB.SEQ_DROP('${target_filter_name}'); # 作成したシーケンス削除SQL呼び出し EOS echo "[`date '+%F %T'`] スキーマ内シーケンス削除 終了" # 実行 echo "[`date '+%F %T'`] インポート開始" eval "${exec_cmd}" result_status=$? echo "[`date '+%F %T'`] インポート終了[終了ステータス=${result_status}]" echo "[`date '+%F %T'`] エラーオブジェクトの再コンパイル 開始" sqlplus -s -l "${target_schema_to}/${target_schema_to_pass}@${oracle_tns}" << EOS EXEC DBMS_UTILITY.COMPILE_SCHEMA('${target_schema_to}', FALSE); EOS echo "[`date '+%F %T'`] エラーオブジェクトの再コンパイル 終了"
SQL
IMPDP_SUBというパッケージを作成し、その中に2つのプロシージャを書いている想定ですが、Function等にしてもよいと思います。
外部キー制約の切り替えSQL
マスタ単位で対応できるように、引数の名称と同じ名称を持つ外部キーのON/OFFを切り替えています。
サンプルコード表示
PROCEDURE SWITCH_FOREIGNKEY ( IS_ENABLE IN CHAR, TARGET_NAME IN VARCHAR2 ) IS -- 自スキーマ内のTARGET_NAMEで設定したテーブルの外部キー制約を取得 -- ループさせるためカーソルで取得 CURSOR CUR_FOREIGN_KEY IS SELECT TABLE_NAME ,CONSTRAINT_NAME FROM USER_CONSTRAINTS WHERE CONSTRAINT_TYPE = 'R' AND TABLE_NAME LIKE '%_' || TARGET_NAME || '_%' ORDER BY TABLE_NAME ,CONSTRAINT_NAME ; BEGIN --取得した外部キー制約の有効・無効を切り替え FOR REC IN CUR_FOREIGN_KEY LOOP IF IS_ENABLE = 'y' THEN -- y指定で有効化 -- 動的SQLのためEXECUTE IMMEDIATEで実行 EXECUTE IMMEDIATE 'ALTER TABLE ' || REC.TABLE_NAME ||' ENABLE NOVALIDATE CONSTRAINT ' || REC.CONSTRAINT_NAME; ELSIF IS_ENABLE = 'n' THEN -- n指定で無効化 EXECUTE IMMEDIATE 'ALTER TABLE ' || REC.TABLE_NAME ||' DISABLE CONSTRAINT ' || REC.CONSTRAINT_NAME || ' CASCADE'; END IF; END LOOP; END SWITCH_FOREIGNKEY;
シーケンスの削除SQL
マスタ単位で対応できるように、引数の名称と同じ名称を持つシーケンスを消すようにしています。
サンプルコード表示
PROCEDURE SEQ_DROP ( TARGET_NAME IN VARCHAR2 ) IS -- 該当する名前を含むシーケンス名を取得 -- ループさせるためカーソルで取得 CURSOR CUR_TARGET_SEQ(TARGET_NAME IN VARCHAR2) IS SELECT SEQUENCE_NAME FROM USER_SEQUENCES WHERE SEQUENCE_NAME LIKE '%_' || TARGET_NAME || '_%' ORDER BY SEQUENCE_NAME BEGIN -- 取得した全シーケンスをDROP FOR REC IN CUR_TARGET_SEQ(TARGET_NAME) LOOP -- 動的SQLのためEXECUTE IMMEDIATEで実行 EXECUTE IMMEDIATE 'DROP SEQUENCE ' || REC.SEQUENCE_NAME; END LOOP; END SEQ_DROP;
これで全部の準備が整いました!
次のようにメインシェルを呼び出して利用できます。
test_PDB :DB名
mst_name :フィルタリングする名前(マスタ名)
dump.dmp :ダンプ名
sh Impdp_ex.sh test_PDB mst_name dump.dmp
後は3つのシェルをテストサーバーにのみ配置して、なるべく元のimpdpは使わない、という運用にすることで誤って本番環境にインポートするのを防ぐようにしました。
感想
うまく機能したので、満足しています。
メンテナンスチームの要望を叶えるためだけではなく、開発チーム内でのデータ検証やテストデータ作成時に頻繁にこのツールを活用しています。
また、最近ではダンプからマスタ毎の復元を何回も行う必要がある業務があったのですが、新しく参画いただいた方にもこのツールを利用して復元に詰まることなく進めることできたので、作成して良かったなと思っています。
明日14日目は、武田さんによる「セルフホストランナーのバックエンドテストCIを1年間運用してみて」です。お楽しみに!
JMDCでは、ヘルスケア領域の課題解決に一緒に取り組んでいただける方を積極採用中です!フロントエンド /バックエンド/ データベースエンジニア等、様々なポジションで募集をしています。詳細は下記の募集一覧からご確認ください。 hrmos.co まずはカジュアルにJMDCメンバーと話してみたい/経験が活かせそうなポジションの話を聞いてみたい等ございましたら、下記よりエントリーいただけますと幸いです。 hrmos.co ★最新記事のお知らせはぜひ X(Twitter)、またはBlueskyをご覧ください! Tweets by jmdc_tech twitter.com bsky.app
