こんにちは、プロダクト開発部の八杉です。JMDC では主に web フロントエンドの実装や設計を中心に行っているほか、最近は Rails の GraphQL モジュールの設計や CI の最適化にも取り組んでいます。
本記事は JMDC Advent Calendar 2023 11日目の記事です。 qiita.com
この記事では、 RuboCop を CI で実行した際に遭遇した cache にまつわる 3 つの問題とその対処について紹介します。
背景
今回お伝えするのは、私が開発に携わる Pep Up (ペップアップ) という web サービスの話です。
Pep Up は Ruby on Rails 製のアプリケーションで、コードフォーマッターに RuboCop を使用しています。8 年前の開発初期から使用していますが、違反のチェックを厳格に行っていなかったこともあり、ここ数年はフォーマット違反が放置されるケースが目立っていました。コードフォーマットの自動化は開発体験上重要ですから、バックエンドのメンバーを中心にしてこの数ヶ月でフォーマット環境の再整備を進めてきました。具体的には、 cops の整理や pre-commit 時の fix 実行や GitHub Actions でのチェックの実施等の仕組みづくりです。
この取り組みにより、違反コードは CI で検知できるようになりました。コードフォーマットの一貫性が担保され、コードレビュー時に些末な指摘をする必要も無くなってみんなハッピーです。2023 年 8 月のことです。
Cache を有効化して RuboCop 実行を高速化する
ところで、コードベースのすべてのファイルに対して RuboCop を実行するととても時間がかかります。Pep Up の場合、 GitHub Actions のデフォルトの runner を使用して 4-5 分程度かかります。頻繁に実行するものですし、 RuboCop には cache 機構 がありますから、当然これを利用して高速化を図りたいところです。
そこで、 cache action を使用して以下のような GitHub Actions ワークフローを構築しました。
name: RuboCop on: pull_request: branches: - main jobs: rubocop-all: runs-on: ubuntu-latest steps: # checkout や ruby の setup 等の処理は省略しています - name: Cache rubocop uses: actions/cache@v3 with: path: ~/.cache/rubocop_cache key: rubocop-${{ hashFiles('.rubocop.yml', '.rubocop_todo.yml', 'Gemfile.lock', '.ruby-version') }} restore-keys: rubocop- - name: Run RuboCop run: bundle exec rubocop --format simple
cache key の妥当性については shibayu36 さんのブログ記事がわかりやすいので紹介しておきます。 blog.shibayu36.org
Cache が効かない (★☆☆)
Pep Up では CI の実行時間を Datadog を使って監視しています。次の画像は上記のワークフローを導入してから 3 週間の実行時間の推移です。縦軸が実行時間 (分) で、4 分の位置にある破線はチームで設けている CI 実行時間の許容基準です。

ご覧の通り、平均で 5 分程度かかっていることが見て取れます。稀に 1 分程度で終わっているケースがあり、ここには cache が効いていそうですが、それ以外の多くのケースでは cache が効いていないようです。
原因
ログを追うと、ほとんどの workflow run で actions cache を見つけられていないことがわかりました。
Cache not found for input keys: rubocop-xxxxxxxxx, rubocop-
原因は main ブランチで cache を生成していないことでした。この挙動については公式ドキュメントに記載があります。
The cache action first searches for cache hits for key and the cache version in the branch containing the workflow run. If there is no hit, it searches for restore-keys and the version. If there are still no hits in the current branch, the cache action retries same steps on the default branch. ...
cache の探索時には最初にそのブランチ (今回は pull_request trigger なので正確には merge ref) の cache がチェックされ、その次に main ブランチの cache がチェックされます。PR 作成時の最初の run では当然そのブランチの cache はまだ存在しませんし、 main ブランチで cache を作成していなければ結果として cache が見つからないことになります。
PR の作成後にコミットを追加して再度 run したときは cache が効きますから、前掲のグラフの凹みはそれで説明がつきます。
対策
ということで、 main ブランチへの pull_request 時だけではなく main ブランチへの push 時にも RuboCop を実行して cache を残すようにします。
on: pull_request: branches: - main push: branches: - main # 追加
Cache が効かない (★★☆)
main ブランチで RuboCop を実行するようになった結果、たしかに効果が見られました。以下のグラフは前掲のグラフの状態から数日進めたものです。
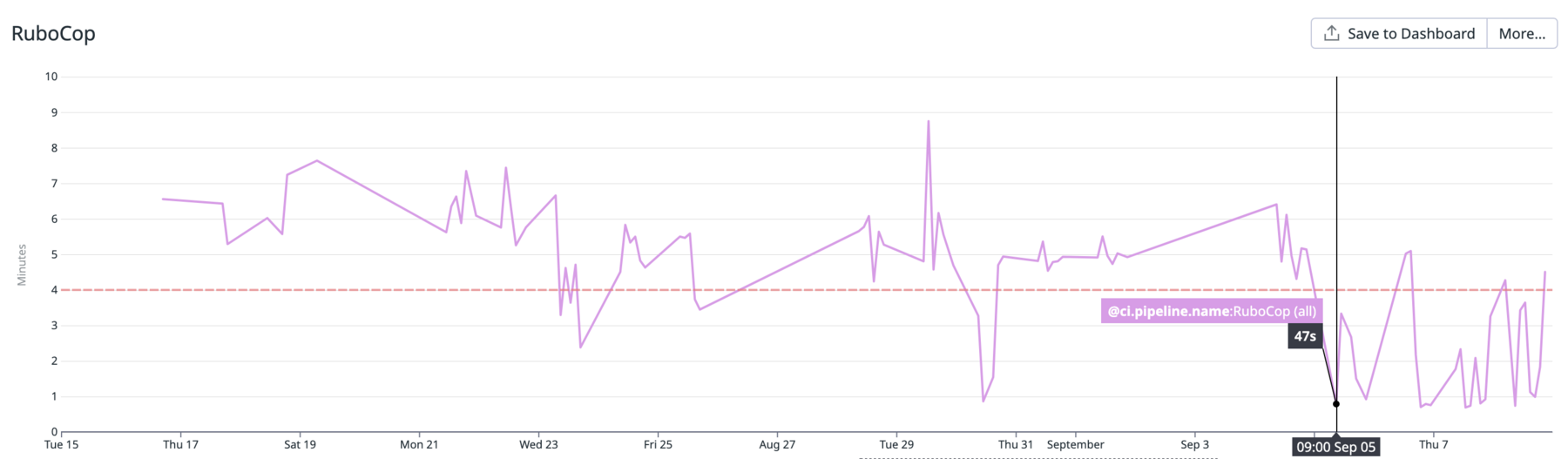
導入日の 9/4 前後を境に実行時間が改善しています。しかし、よく見るとその後もときどき 4 分のラインを超えるケースが見られます。この間 actions cache の key として列挙している 4 つのファイル (.rubocop.yml, .rubocop_todo.yml, Gemfile.lock, .ruby-version) に変更はありません。
workflow run のログを調べると、これらのケースでは actions cache が exact match しているにも拘わらず RuboCop が実行時にそれを利用していないことがわかりました。
つまり、 RuboCop はこれら 4 つのファイルの他にも何らかの条件に基づいて cache を invalid と見なすことがあるようです。cache key の設定が誤っていると cache の効率に影響しますから、 actions cache の key には必要十分な値を指定したいところです。
原因
前掲の shibayu36 さんのブログ記事によれば、 RuboCop の cache は次のような仕組みになっています。
RuboCopは以下のようなキャッシュ構造になっている。
{cache_root}/{rubocop_checksum}/{context_checksum}/{file_checksum}たとえば~/.cache/rubocop_cache/48495939d6d5ca59d7f0a191fd9c11432a988b9d/eb1638cf9f9405f1dfcb03f4d43f86ec4b3f6af5/bab558f367464a4c3a65c3c112fae2e3168613cdのようなファイルに、どんな違反があったかの情報が書かれている。現在RuboCopチェックをかけようとしているファイルのキャッシュがあれば、違反内容は変わらないためキャッシュファイル内に記載された違反内容をそのまま返せば良い。Rubyのバージョン変更、RuboCopの設定変更、RuboCopのオプション変更はrubocop_checksumやcontext_checksumへ影響を及ぼすので、全キャッシュが無効になるようだ。
まったく何も変更がない場合、checksumの計算 + RuboCopチェックをかける分のキャッシュ読み込みのみ行うため、ほぼ一瞬でRuboCopの結果が返ってくるようだ。
そこでログを追うと、 cache が効いていない run では context_checksum の部分に差異があることがわかりました。
ということで、ここで RuboCop のソースコードを見に行ってみます。context_checksum は次のようなコードです。
def team_checksum(team) @checksum_by_team ||= {}.compare_by_identity @checksum_by_team[team] ||= team.external_dependency_checksum end def context_checksum(team, options) Digest::SHA1.hexdigest([team_checksum(team), relevant_options_digest(options)].join) end
ここの team.external_dependency_checksum というコードを見てピンと来ました。Pep Up ではいくつかの RuboCop extension を使用していますから、そこが怪しそうです。
果たして、 extension のコードを一つずつ見ていくと RuboCop Rails のコードにそれらしいものが見つかりました。
def external_dependency_checksum return @external_dependency_checksum if defined?(@external_dependency_checksum) schema_path = RuboCop::Rails::SchemaLoader.db_schema_path return nil if schema_path.nil? schema_code = File.read(schema_path) @external_dependency_checksum ||= Digest::SHA1.hexdigest(schema_code) end
RuboCop Rails が schema.rb の内容を cache key に加えていることがわかりました。
RuboCop Rails は Rails のベストプラクティスにフォーカスした extension です。この extension はどうやら schema.rb の内容を参照して Rails/UniqueValidationWithoutIndex のような制約のチェックに利用しているようです。そのために schema.rb に変更があったときは cache を invalidate する必要があるわけですね。納得です。
対策
ということで、 actions cache の key に schema.rb を含めるようにします。
また、 RuboCop の cache invalidation に影響を与える gem はごく一部ですから、 Gemfile.lock が更新されるたびに actions cache を破棄するのは効率が悪そうです。そこで、次のように Gemfile.lock のセクションを分離して cache 効率の最適化も図ります。
- name: Cache rubocop uses: actions/cache@v3 with: path: ~/.cache/rubocop_cache key: rubocop-${{ hashFiles('.rubocop.yml', '.rubocop_todo.yml', '.ruby-version', 'db/schema.rb') }}-${{ hashFiles('Gemfile.lock') }} restore-keys: | rubocop-${{ hashFiles('.rubocop.yml', '.rubocop_todo.yml', '.ruby-version', 'db/schema.rb') }}- - name: Run Rubocop run: bundle exec rubocop --format simple
Cache が効かない (★★★)
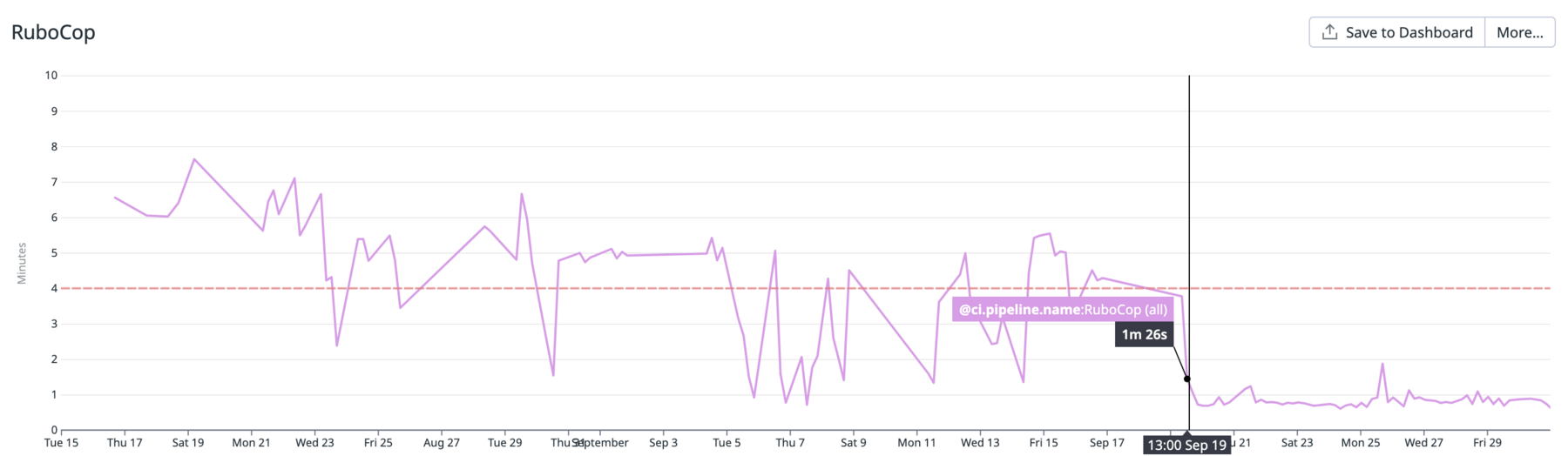
これで解決したかと思いましたが、問題はまだ続きます。次のグラフは前項の対策を導入後 1 週間ほど経過したときの状態です。

9/8 に対策を導入したものの、それ以降も状況がほとんど改善していません。これはどういうことでしょうか。
原因
前回の調査時には気が付きませんでしたが、 ログを調べると rubocop_checksum の方も意図しないタイミングで変化していることがわかりました。
RuboCop の cache 構造を再掲しておきます。
{cache_root}/{rubocop_checksum}/{context_checksum}/{file_checksum}
ということで、さらに調査していると次の issue にたどり着きました。
問題の概要から原因と解決策にいたるまでこの方が詳細にまとめてくれていますが、この問題は次のように説明されます。
- RuboCop は自身が require する feature の集合 (
rubocop_required_features) を rubocop_checksum の計算に利用する- 自身が require する feature とは、 rubocop.rb を実行後の
$LOADED_FETURESから実行前時点の$LOADED_FETURESの値を除いたものである
- 自身が require する feature とは、 rubocop.rb を実行後の
- cache directory (~/.cache/rubocop_cache) が存在しないときだけ rubocop.rb の実行前に fileutils を使った directory 作成処理が呼ばれる
- rubocop.rb の実行時に fileutils が require される
- ゆえに、実行時の cache directory の有無に応じて
rubocop_required_featuresの値が変化し、 rubocop_checksum は異なる値を返すことになる
今回のケースに当てはめると、 RuboCop の cache がほとんど効かなかったのは次の機序によります。
- cache directory (.cache/rubocop_cache) が存在しない状態で RuboCop を実行し、その結果が actions cache に保存される
- 後続の run では 1. で作成された actions cache が exact match して復元される
- 今回は cache directory が存在する。rubocop_checksum の値が 1. とは異なるため RuboCop は cache を利用できない
- exact match なので actions cache は更新されない
- 2. に戻る
対策
ということで、 issue で提示されているワークアラウンドの通り、 RUBYOPT 環境変数を指定して fileutils を事前に require しておくようにします。これにより rubocop_required_features から fileutils が常に除外されるため rubocop_checksum の生成が安定するというわけです。
- name: Run RuboCop run: RUBYOPT='-rfileutils' bundle exec rubocop --format simple
ただし、 fileutils の問題に関しては今後 RuboCop 側で修正される可能性もありますから、あくまで 2023-12 現在のワークアラウンドであるということは書き添えておきます。
ともあれ、ようやく無事に cache が効くようになりました。導入日の 9/19 以降に実行時間が劇的に改善していることがわかります。これで一件落着です。
最終的な workflow yaml は以下のようになりました。
name: RuboCop on: pull_request: branches: - main push: branches: - main jobs: rubocop-all: runs-on: ubuntu-latest steps: # checkout や ruby の setup 等の処理は省略しています - name: Cache rubocop uses: actions/cache@v3 with: path: ~/.cache/rubocop_cache key: rubocop-${{ hashFiles('.rubocop.yml', '.rubocop_todo.yml', '.ruby-version', 'db/schema.rb') }}-${{ hashFiles('Gemfile.lock') }} restore-keys: | rubocop-${{ hashFiles('.rubocop.yml', '.rubocop_todo.yml', '.ruby-version', 'db/schema.rb') }}- - name: Run RuboCop run: RUBYOPT='-rfileutils' bundle exec rubocop --format simple
おわりに
この記事では、 RuboCop を CI で実行した際に遭遇した cache にまつわる 3 つの問題とその対処について紹介しました。cache を最適化することで、初めは 5 分以上かかっていたテストを最終的には 1 分以内に収めることができました。CI の最適化や開発体験の向上については他にも取り組んでいることがありますので、また機会があれば記事にしたいと思います。
明日12日目は山本さんです。お楽しみにー
JMDCでは、ヘルスケア領域の課題解決に一緒に取り組んでいただける方を積極採用中です! フロントエンド /バックエンド/ データベースエンジニア等、様々なポジションで募集をしています。 詳細は下記の募集一覧からご確認ください。
まずはカジュアルにJMDCメンバーと話してみたい/経験が活かせそうなポジションの話を聞いてみたい等ございましたら、下記よりエントリーいただけますと幸いです。
★最新記事のお知らせはぜひ X(Twitter)をご覧ください!
