株式会社JMDCに6月に入社しました @dtaniwakiこと谷脇です。
現在、Pep Up for WORKという企業向けヘルスケアプロダクトをフルスタックで開発しており、今回は開発プロセス改善の取り組みについて紹介させていただきます。
Pep Up for WORKではtoBサービスとしての品質を担保するため、PdMによる動作確認を行っています。一方で、非同期で開発に参加しているメンバーが多いため、この動作確認の効率化が非常に重要となっています。
以前の動作確認フローと仕組み
私が入社する前は、ステージング環境とは別にdev環境というPdM確認用環境を1つ用意して、以下のようなフローでデプロイを行い、PdMが動作確認をしていました。
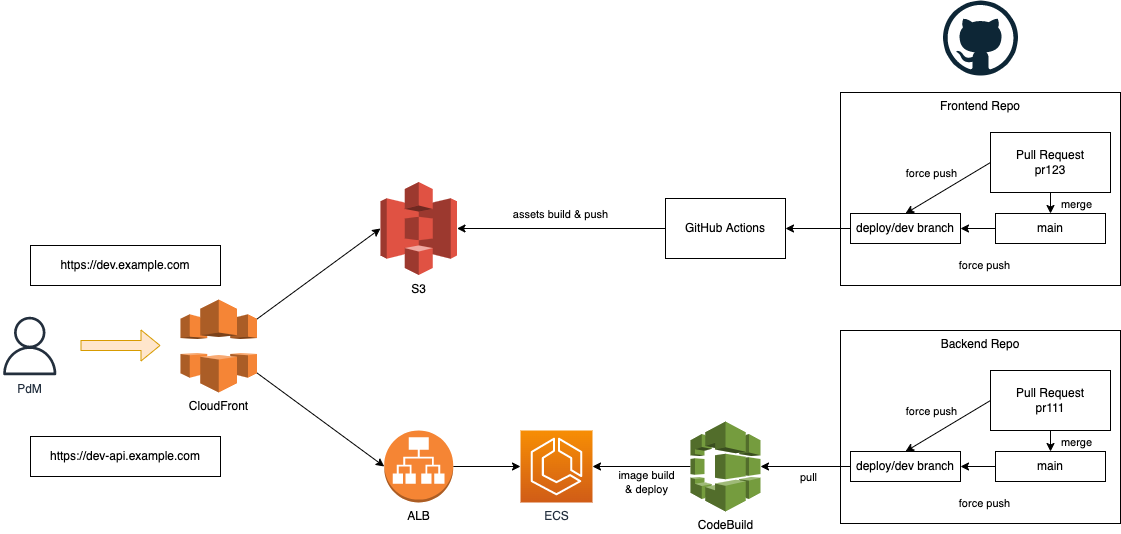
このフローでは以下の2通りのパターンのデプロイが行われます。
- 複数のGitHub PullRequest (以下PR) を確認したい時 -> mainにマージした後にmainからdeploy/devにforce push
- PRをmainにマージする前に確認したい時 -> 直接deploy/devにforce push
SPAのため、フロントエンド・バックエンドそれぞれのリポジトリごとに以下の方法でデプロイが行われます。
# フロントエンド
- dev.example.comは常に特定のS3バケットを指している。
- deploy/devブランチのpushイベントでGitHub ActionsがビルドしたassetsをS3にアップロードする。
# バックエンド
- dev-api.example.comは常に特定のECSを指している。
- deploy/devブランチに対し、CodeBuildでDockerイメージをビルドする。
- CodePipelineがECSにデプロイする。
以前の動作確認フローの問題
すぐにわかると思いますが、このフローには以下のような問題点があります。
- PRからデプロイする場合
- PdMがテストを終えるまで次のデプロイができず、非同期なはずなのに作業がキューに詰まる。
- さらに悪いことにこのキューのやり取りがチャットで非同期に行われる。
- DBマイグレーションを含んだデプロイは不可逆のためデプロイできない。
- mainからデプロイする場合
- デプロイ後に各PRの実装に問題が発覚した場合、問題切り分け・修正の手間がかかる。
- その他
- デプロイされたFrontendとBackendで常に互換性を保つ必要がある。
これらの制約を加味して作業フローを図にしてみると、以下のようになります。

これだと非同期作業の効率が悪く、開発生産性が著しく低くなってしまっています。
そこで、入社後に動作確認フローを大幅に改善してみました!
新しい動作確認フローと仕組み
改善するに当たってPdMと相談し、以下の要件を満たすように仕組みを構築し直しました。
- PdMが同時に依存なく複数のPRをテストできる。
- PR作成者が任意のタイミングで環境を構築できる。
- PR毎のテストでもDBマイグレーションを実行できる。
- フロントエンドおよびバックエンドのどちらかのテストではもう片方はmainブランチに対してテストできる。
- できるだけインフラコストを増加させたくない。
仕組みは以下になります。
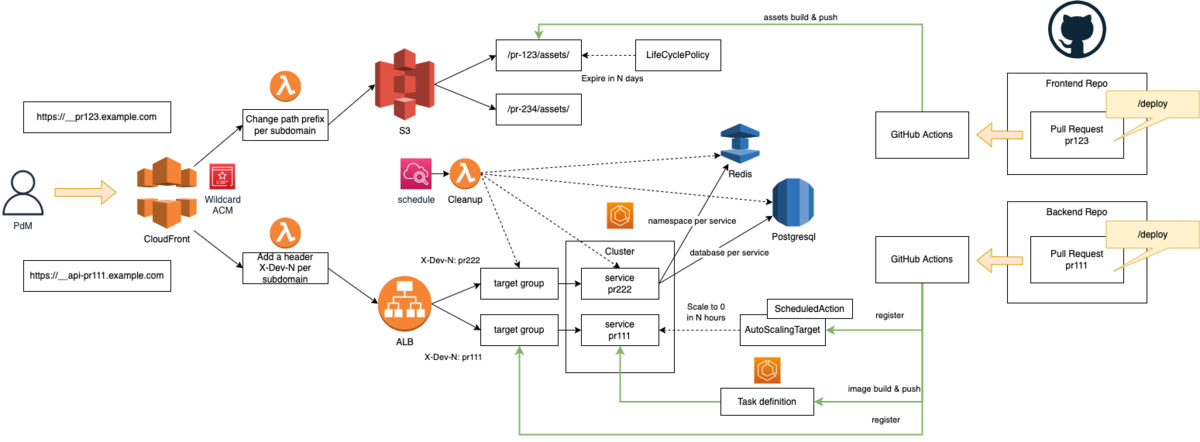
フロントエンド・バックエンドそれぞれのデプロイのフローを説明します。
# フロントエンド
- PR (pr123)上のコメントで/deployと入力する。
- GitHub Actionsでアセットファイルをビルドし、S3のpr123/というパスにアップロードする。
- アップロードしたファイルの有効期限をセットすることで、一定期間後に自動的にファイルが削除されるようにする。
- CloudFrontのLambda@EdgeでPR毎のサブドメインをS3のパスに変換して配信する。
# バックエンド
- PR (pr111)上のコメントで/deployと入力する。
- GitHub Actionsでコンテナイメージをビルドし、ECRにpr111のタグでPushする。
- ベースとなるECS TaskDefinitionに対して、このイメージを使うように上書きしたTask Definitionを作成する。
- このTask Definitionを使ったECS Serviceを立ち上げ、あらかじめ用意されたALBでHTTPヘッダにX-Dev-N: pr111がある場合はこのServiceにルーティングさせる。
- ECSのScheduledActionをセットすることで、一定期間後に自動的にコンテナ数が0にスケールするようにする。
- CloudFrontのLambda@EdgeでPR毎のサブドメインをX-Dev-Nヘッダに変換してALBにリクエストを渡す。
コンテナは自動で落ちるのでコストは抑えられますが、ALBのルールとコンテナ数が0のECS Serviceが残ってしまうので、これはCloudWatch EventsでLambdaを実行して掃除してあげます。
さらに、フロントエンド・バックエンドの任意の組み合わせをテストできるよう、GitHubの/deployコメントに--backendオプションを導入しました。

PdMが気付きやすいように、デプロイが成功したらGitHub Actionsからデプロイされた環境のURLが通知されるようにしました。

この改善後の開発フローを図にしてみると、以下のように効率よく進められるようになったことがわかります。

これにより、非同期開発でのPdMの動作確認の効率が圧倒的に改善され、2ヶ月に1度のデプロイを1週間に1回まで頻度を上げることができました!
JMDCでは質の高いサービスを顧客に提供し事業を成長させるため、常に開発プロセスの改善に取り組んでいます。今後も我々の取り組みを少しずつ記事にしていきますので、フィードバックやコメントをいただけたら幸いです!
