みなさん、こんにちは!株式会社JMDC データウェアハウス開発部 医療機関基盤Gの平木です。
今年、JMDCではアドベントカレンダーに参加しています。
本記事は、JMDC Advent Calendar 2024 1日目の記事です。 この後も記事をどんどん出す予定なので、チェックのほどよろしくお願いいたします!
はじめに(導入)
私のチームでは、医療機関が診療報酬を請求する際に必要なレセプトデータを加工して、サービス向けのデータマートを作成しています。
このレセプトの入力仕様はかなり複雑な仕様となっており、一からテストデータを作成しようとすると大変です。
今回はそのようなレセプトのテストデータをRAG(Retrieval-Augmented Generation)を用いて、正確に自動生成できるかをチャットアプリを作って試したいと思います。
レセプトとは?
「レセプト」とは、医療機関が診療報酬を請求するために作成するデータのことです。患者が受けた医療サービスや処方された薬品などの詳細が記載されており、保険者(健康保険組合や国民健康保険など)に提出されます。これに基づいて、医療機関は診療報酬を受け取ります。
以下のようにレコード種別ごとに入力する内容が決まっており、正規化されていないCSVデータとなります。
「診療報酬のオンライン又は光ディスク等による請求に係る記録条件仕様(医科用)」で定義されています。
IR,2,46,1,1234567,,病院名,202405,00,0011112222 RE,1,1111,202404,サンプル太郎,1,19500101,70,20240414,,1,30,,,,,,*,,,,01,,,,,,,,,,,,,,,*, HO,12345678,....,*,4,12345,00,9,2222,,,35400,,, SN,1,01,,,,01,, JD,1,,,,,,,,,,,,,,1,1,1,1,,,,,,,,,,,,,, MF,01,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, ....
RAG(Retrieval-Augmented Generation)とは?
RAG(Retrieval-Augmented Generation)とは、LLMによるテキスト生成時に、外部情報を検索して組み合わせることで、回答精度を向上させる技術です。
今回は、「診療報酬のオンライン又は光ディスク等による請求に係る記録条件仕様(医科用)」を参照させることで、この仕様に従ったレセプトデータの生成ができることを期待しています。
次のシステム構成を見ていただくとイメージしやすいかと思います。
今回作成した検証用のシステム構成
StreamlitでPDFのアップロード画面とチャット画面を作成しました。以下はシステムの全体像です。
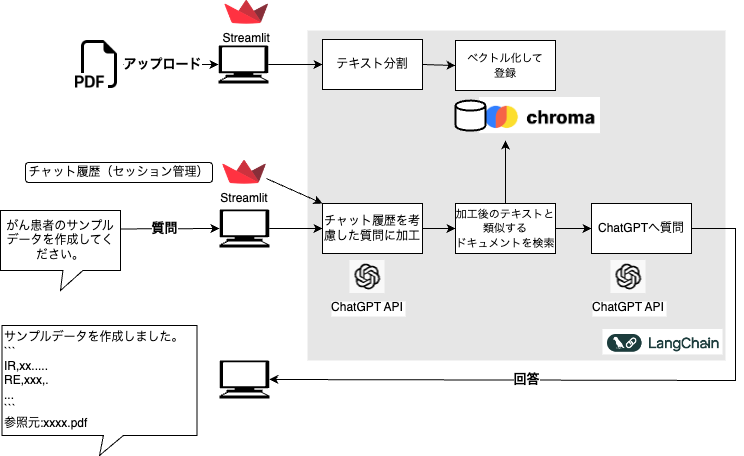
- PDFアップロード:Streamlit上でPDFをアップロードし、テキストデータとして取り込みます。
- テキスト処理:テキストを分割し、ベクトル化してchromaに保存します。(検索はこのテキスト単位になります)
- 質問処理:ユーザーの質問に対し、過去のチャット履歴を考慮した質問内容に加工します。
- ドキュメント検索:関連するドキュメントを検索します。
- 回答生成:加工後の質問内容と検索したドキュメントを元に回答用のプロンプトを作成して、ChatGPT APIに質問にします。
- 回答処理:結果をユーザーに表示します。
ベクトルデータベースにはchromaを、LLMにはChatGPTを使用しました。これらをオープンソースフレームワークのLangChainから操作します。
プロンプトの確認
実装方法は色々な記事に上がっているので、プロンプトに注目してみます。
質問処理から回答生成まではLangChainを用いることで、create_retrieval_chain(リファレンス)というメソッドだけで実行が可能となります。
LangChainのリファレンスにあるものをそのまま使用したため、質問処理と回答生成ではどういったプロンプトを作成しているのか確認します。
まずは質問処理です。該当箇所を確認すると以下のようになっています。 つまりシステムプロンプトで、チャット履歴と最新のユーザー質問から1つの質問に再構成するように指示しています。
contextualize_q_system_prompt = (
"Given a chat history and the latest user question "
"which might reference context in the chat history, "
"formulate a standalone question which can be understood "
"without the chat history. Do NOT answer the question, "
"just reformulate it if needed and otherwise return it as is."
)
# 日本語訳
# チャット履歴と最新のユーザー質問が与えられている場合、
# その質問がチャット履歴の文脈を参照している可能性があります。
# チャット履歴なしでも理解できるように、
# 独立した質問として再構成してください。質問に答えず、
# 必要に応じて再構成し、それ以外の場合はそのまま返してください。
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
次に回答生成時のプロンプトを確認します。
検索されたcontextを使って回答するようにと指示しています。このcontextにドキュメント検索結果が含まれることになります。
また、最大で3文で簡潔にというのは今回のテストデータ作成には適してなさそうですがそのまま使用します。
system_prompt = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
"{context}"
)
# 日本語訳
# あなたは質問応答タスクのためのアシスタントです。
# 与えられたcontextを使って質問に答えてください。
# もし答えが分からない場合は、その旨を伝えてください。
# 最大で3文で答え、簡潔にまとめてください。
# \n\n
# {context}
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
精度評価
モデルは両方とも4oを使用しました。
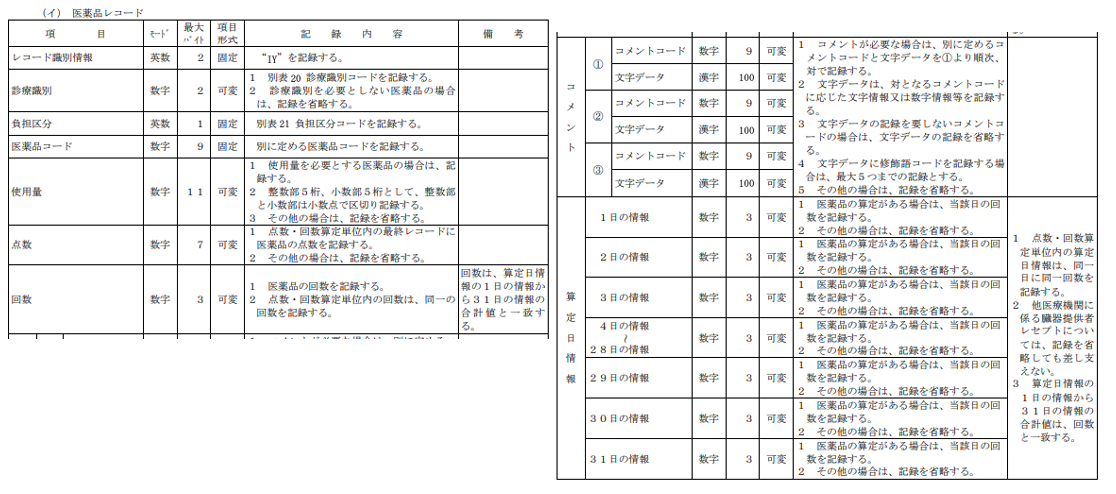
軽く試したところ、複数のレコード種別データを作成するのは難しそうだったため、医薬品レコード(IY)を作成できるかを評価します。算定日情報は「4日の情報〜28日の情報」と集約されていたり、人間が読んでも少し悩むような記載になっています。
※以降はポイントだけ記載するので、レセプトの詳細仕様は理解しなくても大丈夫です。
ChatGPT単体での精度
そもそもレセプトのレコード種別の知識があるのかを確認します。

何も指定しなくとも、該当のファイルを検索した上で回答してくれましたが、実際には存在しない入力項目が含まれています。
この時点でChatGPT単体ではテストデータの作成は難しそうですが、依頼してみます。
これまでの履歴が影響しないように、新しいチャットで実施します。

やはり現時点でChatGPT単体では難しいようです。
RAGでの精度
「診療報酬のオンライン又は光ディスク等による請求に係る記録条件仕様(医科用)」のPDFをアップロードした上で、同様にレコード種別の知識があるのかを確認します。
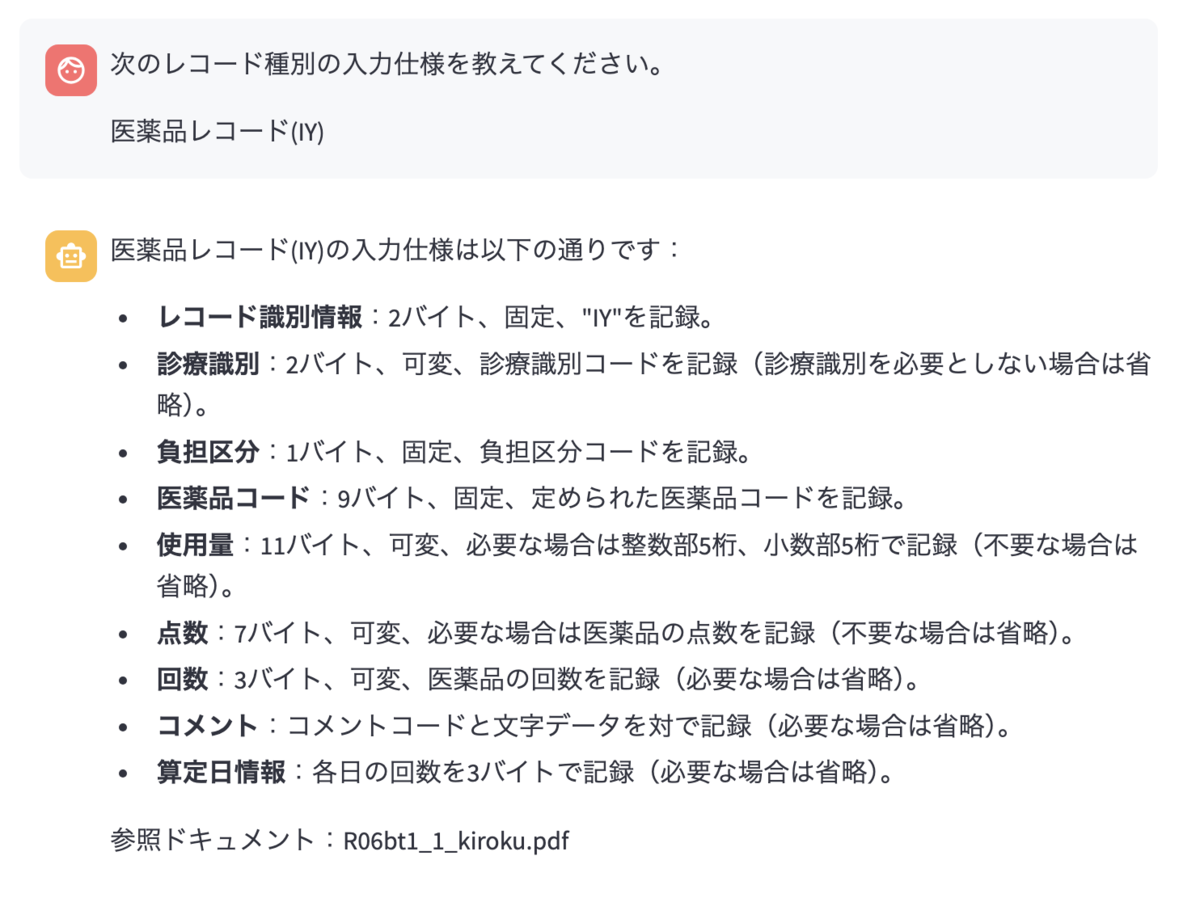
正しく回答してくれています!次にデータの作成を依頼します。

解釈の難しい算定日情報まで作成してくれました!
ただ、よく確認すると、算定日のヘッダは31日までありますが、データは28日分しか作成されていません。
この辺りはプロンプトでデータなしのカラムも空列にするような指示が必要そうです。
レコード識別情報,診療識別,負担区分,医薬品コード,使用量,点数,回数,コメントコード1,文字データ1,コメントコード2,文字データ2,コメントコード3,文字データ3,1日の情報,2日の情報,3日の情報,4日の情報,5日の情報,6日の情報,7日の情報,8日の情報,9日の情報,10日の情報,11日の情報,12日の情報,13日の情報,14日の情報,15日の情報,16日の情報,17日の情報,18日の情報,19日の情報,20日の情報,21日の情報,22日の情報,23日の情報,24日の情報,25日の情報,26日の情報,27日の情報,28日の情報,29日の情報,30日の情報,31日の情報 IY,01,A,123456789,10.00000,100,1,001,コメント1,002,コメント2,003,コメント3,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1
回答生成時にcontextに設定された検索ドキュメントを確認します。
Document(metadata={'page': 21, 'source': '/app/pdfs/R06bt1_1_kiroku.pdf'}, page_content='- 18 - \n (イ) 医薬品レコード \n項 目 モード 最大 \nバイト 項目 \n形式 記 録 内 容 備 考 \nレコード識別情報 英数 2 固定 “IY”を記録する。 \n診療識別 数字 2 可変 1 別表20 診療識別コード を記録する 。 \n2 診療識別を必要としない 医薬品の場合\nは、記録を省略する。 \n負担区分 英数 1 固定 別表21 負担区分コード を記録する。 \n医薬品コード 数字 9 固定 別に定める医薬品コードを記録する。 \n使用量 数字 11 可変 1 使用量を必要とする医薬品の場合は 、記\n録する。 \n2 整数部5桁、小数部5桁として、整数部\nと小数部は小数点で区切り記録する。 \n3 その他の 場合は、記録を省略する。 \n点数 数字 7 可変 1 点数・回数算定単位内の最終レコード に\n医薬品の点数を 記録する。 \n2 その他の 場合は、記録を省略する。 \n回数 数字 3 可変 1 医薬品の回数を記録する。 \n2 点数・回数算定単位内の回数は、同一の\n回数を記録する。 回数は、算定日情\n報の1日の情報か\nら31日の情報 の\n合計値と一 致す\nる。 \nコ \nメ \nン \nト ① コメントコード 数字 9 可変 1 コメントが必要な場合は、別に定めるコ\nメントコードと文字データを①より順次、\n対で記録する。 \n2 文字データは、対となるコメントコード\nに応じた文字情報又は 数字情報 等を記録す\nる。 \n3 文字データの記録を要しないコメントコ\nードの場合は、文字データの記録を省略す\nる。 \n4 文字データに修飾語コードを記録する場\n合は、最大5つまでの記録とする。 \n5 その他の 場合は、記録を省略する。 文字データ 漢字 100 可変 \n② コメントコード 数字 9 可変 \n文字データ 漢字 100 可変 \n③ コメントコード 数字 9 可変 \n文字データ 漢字 100 可変 \n算 \n定 \n日 \n情 \n報 1日の情報 数字 3 可変 1 医薬品の 算定がある場合は、当該日の回\n数を記録する。 \n2 その他の 場合は、記録を省略する。 \n1 点数・回数算\n定単位内の算定\n日情報は、同一\n日に同一回数を\n記録する。 \n2 他医療機関に\n係る臓器提供者\nレセプトについ\nては、記録を省\n略しても差し支\nえない。 \n3 算定日情報の\n1日の情報から\n31日の情報の\n合計値は、回数\nと一致する。 2日の情報 数字 3 可変 1 医薬品の算定がある場合は、当該日の回\n数を記録する。 \n2 その他の場合は、記録を省略する。 \n 3日の情報 数字 3 可変 1 医薬品の算定がある場合は、当該日の回\n数を記録する。 \n2 その他の場合は、記録を省略する。 \n4日の情報 \n \n~ \n28日の情報 数字 3 可変 1 医薬品の算定がある場合は、当該日の回\n数を記録する。 \n2 その他の場合は、記録を省略する。 \n29日の情報 数字 3 可変 1 医薬品の算定がある場合は、当該日の回\n数を記録する。 \n2 その他の場合は、記録を省略する。 \n30日の情報 数字 3 可変 1 医薬品の算定がある場合は、当該日の回\n数を記録する。 \n2 その他の場合は、記録を省略する。 \n31日の情報 数字 3 可変 1 医薬品の算定がある場合は、当該日の回\n数を記録する。 \n2 その他の場合は、記録を省略する。
正しく医薬品レコードのページ部分を渡せています。(これを表として認識しているのはすごいですね。)
比較
ChatGPT単体に比べるとRAGを用いることで、以下のメリットがあることがわかりました。
- 存在しない項目を出力することは無くなる。(ハルシネーションの軽減)
- 1度アップロードしておけば、ドキュメントを指定する必要がなくなる。
課題と対策
一方で実際にテストデータを作るには以下課題があることがわかりました。考えられる対策と合わせて挙げてみます。
| 課題 | 対策 |
|---|---|
| 精度が安定しない 複数のレコード種別への対応ができていない 実際にとりえる値でデータを作成できない |
表をマークダウンにするなど質の良い参照DBを構築する 別表を参照させる仕組みを作る ドキュメント検索方法のチューニングをする テストデータ作成に特化したプロンプトをチューニングする |
まとめ
今回、RAGを用いてレセプトのテストデータ生成を試してみました。
現状、ChatGPT単体よりも精度高く作成できますが、実際に開発で使うためには色々な課題があることがわかりました。
とはいえ、RAGの研究も進んでおり、やり方次第では実現もそう遠くないと感じました。
元々、LLMを用いたチャットアプリを作ってみたくて始めたのですが、業務適用を考えることでRAGの解像度が上がってよかったです。
明日2日目は、中澤さんによる「AI時代のweb初学者が心がけていること」です。お楽しみに!
JMDCでは、ヘルスケア領域の課題解決に一緒に取り組んでいただける方を積極採用中です!フロントエンド /バックエンド/ データベースエンジニア等、様々なポジションで募集をしています。詳細は下記の募集一覧からご確認ください。 hrmos.co
まずはカジュアルにJMDCメンバーと話してみたい/経験が活かせそうなポジションの話を聞いてみたい等ございましたら、下記よりエントリーいただけますと幸いです。 hrmos.co
★最新記事のお知らせはぜひ X(Twitter)、またはBlueskyをご覧ください!
