こんにちは!最近AWSコストが気になっている保険者レセプトグループの竹内です。
今年、JMDCではアドベントカレンダーに参加しています。
本記事は、JMDC Advent Calendar 2025 4日目の記事です。
皆さんはAWSのコスト管理、どうしていますか?
AWSにはCost Explorerという便利な可視化サービスがありますが、グラフで「S3の料金が上がっている」ことはわかっても、「じゃあ、どのS3バケットが一番コストを食っているの?」と、具体的なリソースIDまで特定できず、もどかしい思いをしたことはないでしょうか。
私自身、この問題に直面し「もっと詳細なコストデータが見たい!」と強く感じていました。
そのニーズを満たす機能として「データエクスポート(CUR 2.0)」というものが存在することに気が付きました。
これは、コストと使用状況に関する最も詳細な生データをS3バケットに直接出力してくれる機能です。
この記事では、私が実際にこの「データエクスポート」を設定し、
Amazon Athenaで分析できる環境を構築するまでの手順と、その過程で発見した「注意事項」を紹介したいと思います。
- 1. データエクスポート(CUR 2.0)の作り方【コンソール画面編】
- 2. データエクスポート(CUR 2.0)の作り方【CloudFormation編】
- 3. Athenaで参照する際の注意事項
- 4. データエクスポート活用法
- 5. 最後に
1. データエクスポート(CUR 2.0)の作り方【コンソール画面編】
まずは基本となる、AWSマネジメントコンソールを使った作成手順です。
CloudFormationに慣れてない方やAWS触り始めの方はこちらの手順でまずは作ってみると理解しやすいと思います。
1. 「請求とコスト管理 (Billing and Cost Management)」コンソールへ移動します。

2. 左側メニューから「データエクスポート」を選択します。
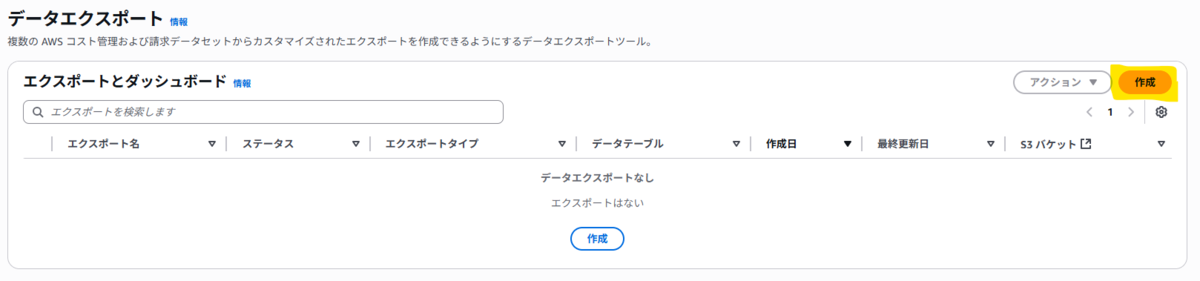
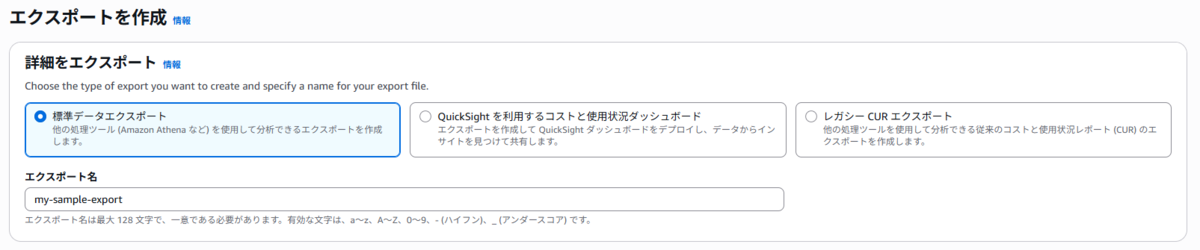
3. 画面の「作成」をクリックし、「標準データエクスポート」を選択し、エクスポート名(例: my-cost-analysis-report)を入力します。
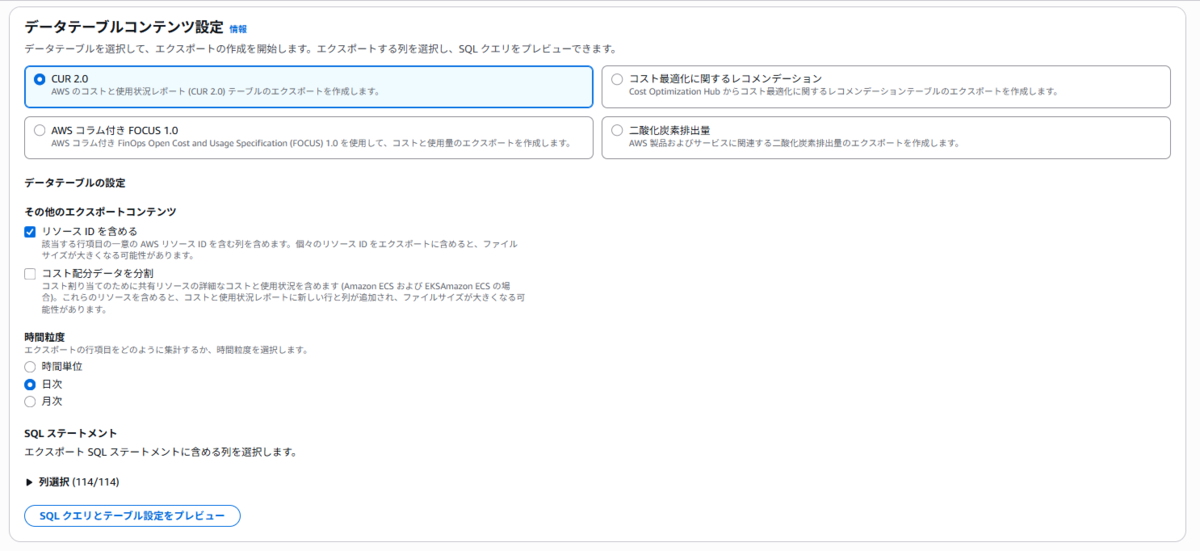
4. 「データテーブルコンテンツ」セクションで、「CUR 2.0」を選択します。
レポートの詳細設定は以下の選択がおすすめです。
* 時間単位: 日単位 (Daily)
* (時間単位はデータが膨大になりすぎ、月単位は分析には粗すぎるため、「日単位」が最もバランスが取れています)
* ファイル形式: Parquet
* (CSVよりクエリが高速で、データスキャン料金も安くなります)
* リソースIDを含める: 必ずチェックを入れる
* (これこそが、今回我々が欲しかった情報です!)
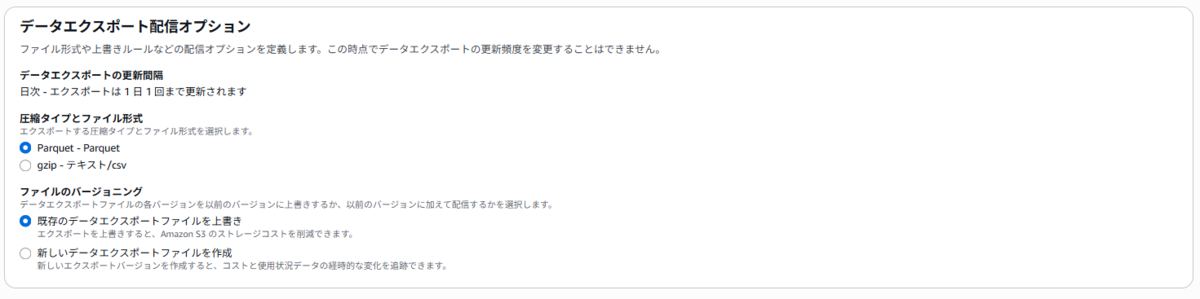
5. 出力先のS3バケットを指定します。
 バケットはこの時に作成することも可能です。私は東京リージョンに作るように設定しました。
バケットはこの時に作成することも可能です。私は東京リージョンに作るように設定しました。
(デフォルトがバージニア北部です)
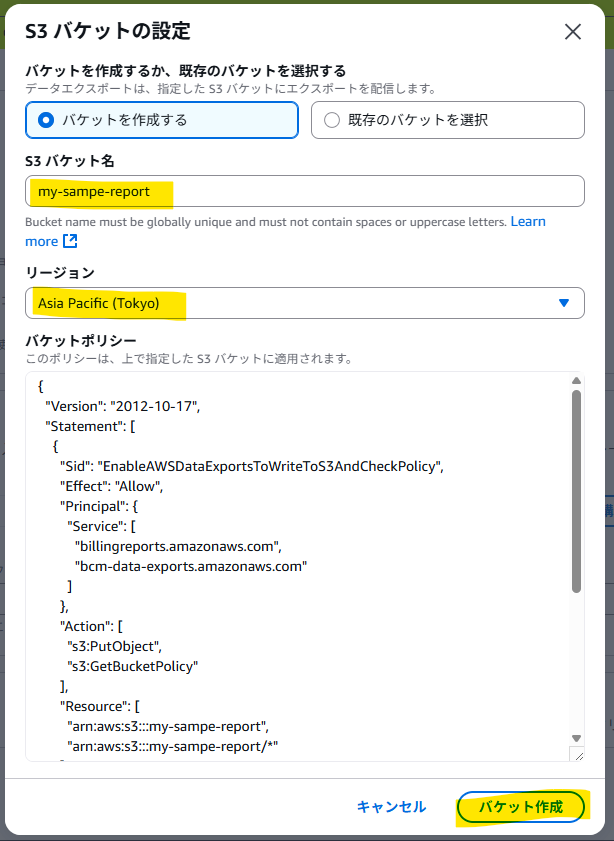
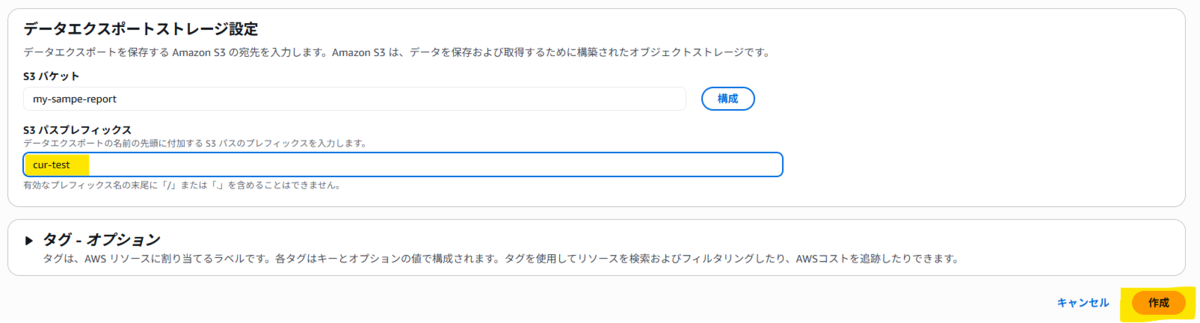
6. 設定内容を確認し、作成を完了します。
これで、24時間以内に指定したS3バケットに最初のレポートが出力されます。
 作成直後のバケットにはまだなにも出力されていません。気長に待ちましょう。
作成直後のバケットにはまだなにも出力されていません。気長に待ちましょう。
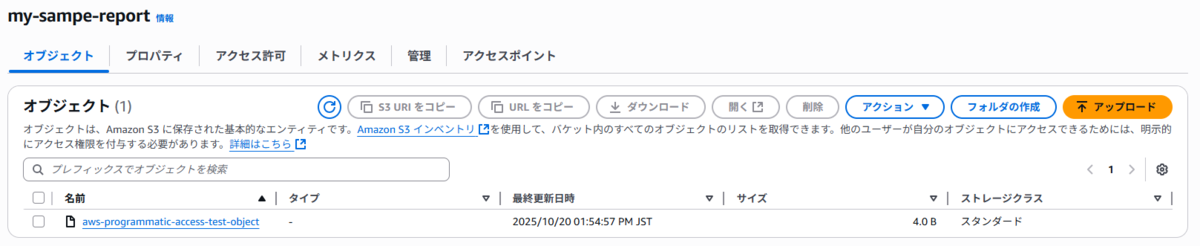
次の日、S3バケットにレポートが出力されていることが確認できました。
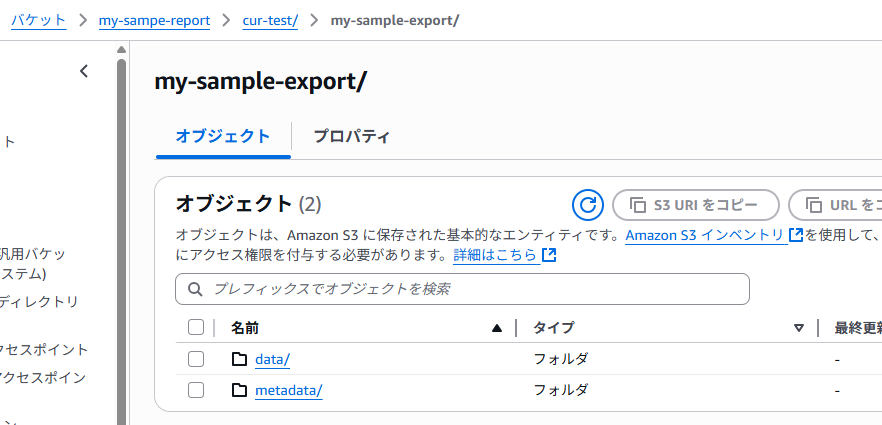 ファイルはparquet形式になっています。
ファイルはparquet形式になっています。
このままではデータが見られないので、Crawlerでデータカタログを作成します。
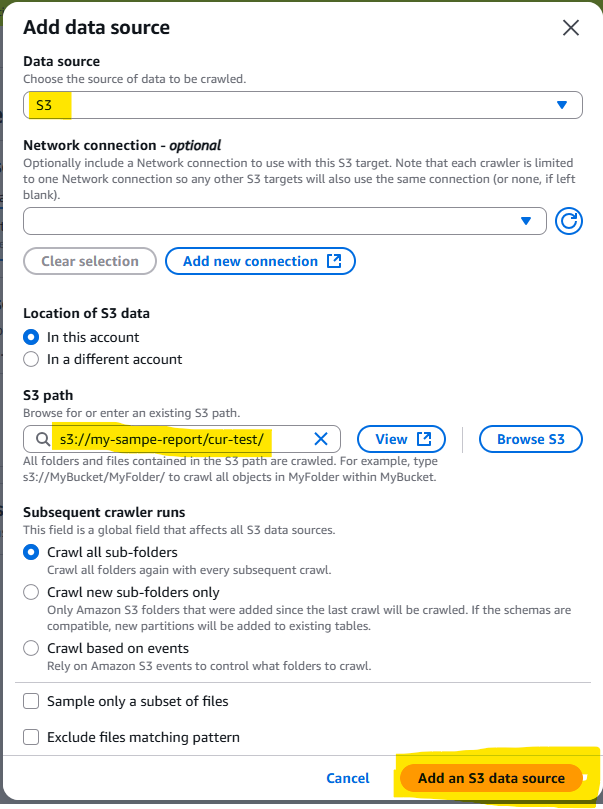
7. わかりやすい名前をつけ、データソースはデータエクスポート出力先のバケットを指定します。
 S3バケット:
S3バケット:
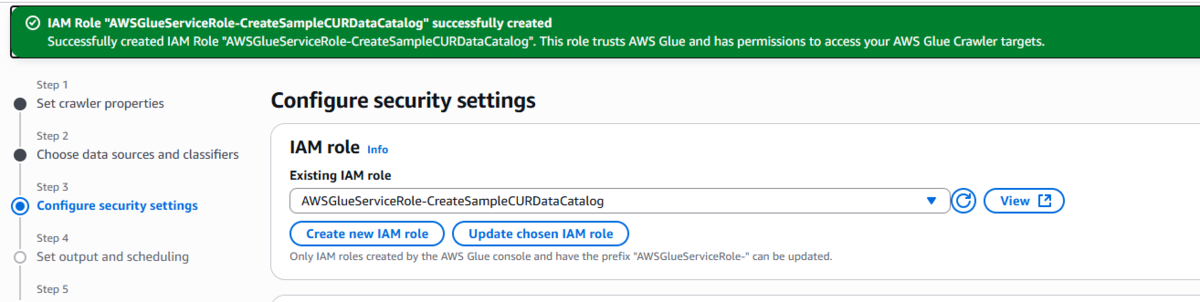
8. IAMロールやGlueデータベースは用意したものがなければ新規作成しながら画面を進めていきます。
IAM:
 Glue Database:
Glue Database:
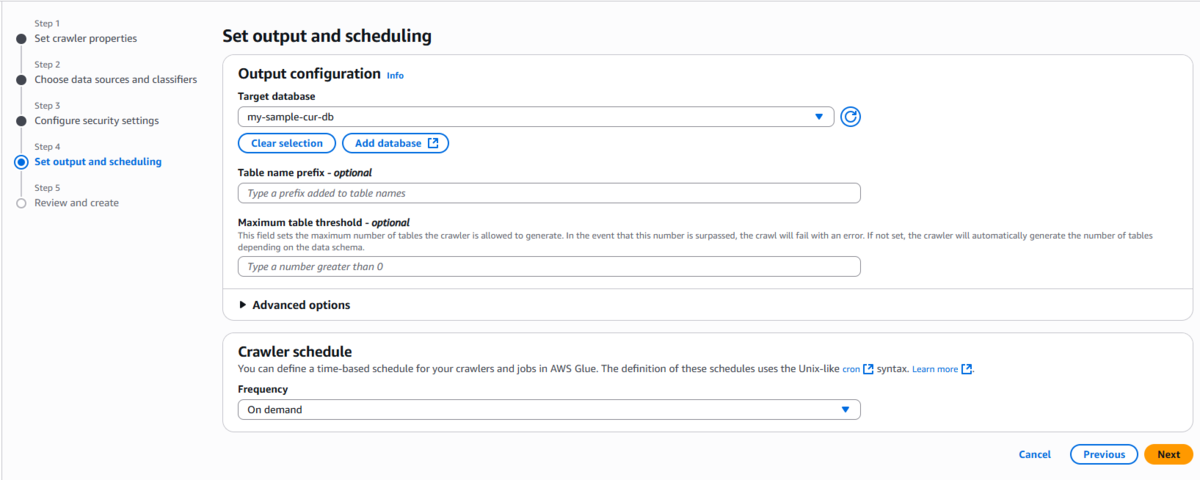
設定内容は以下のようになりました。
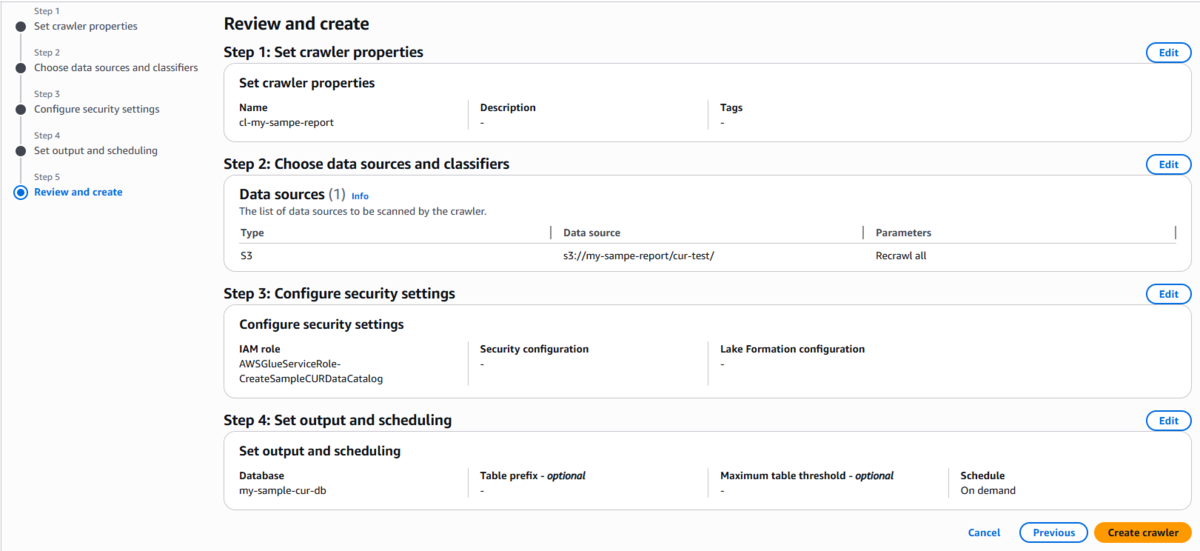
9. Crawlerを実行すると、テーブルが作成されます。

10. やっとAthenaでデータを確認することができました!
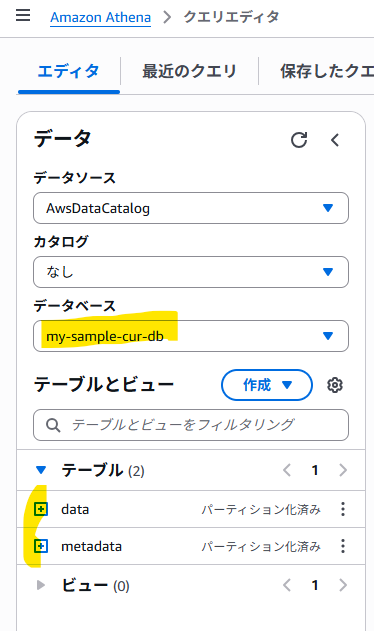
SQLで中身がばっちり見えます。
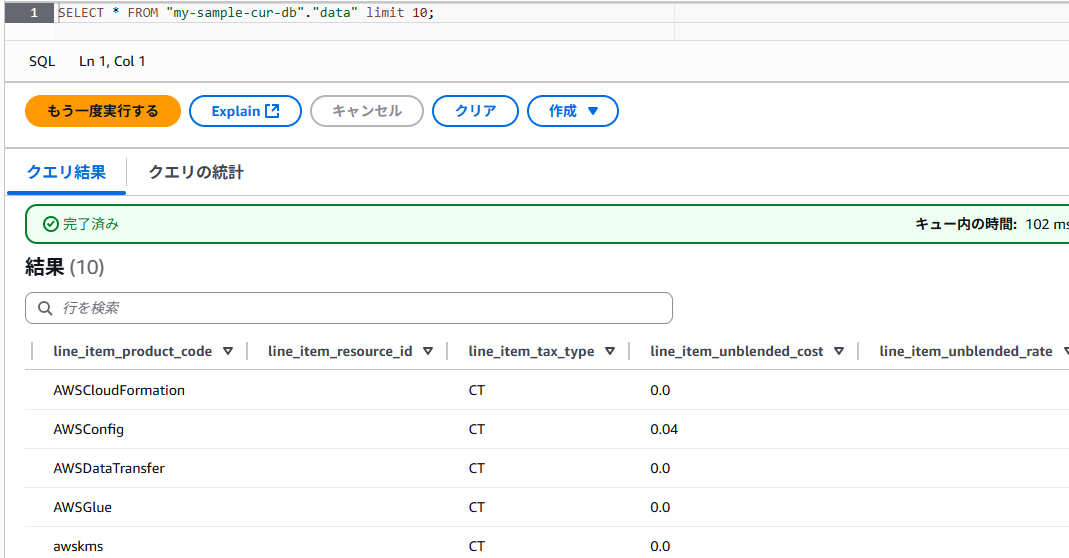
さて・・・・
ここまで手作業で作成してみて、「この手順を他の環境でもやるのは手間だな・・・」と感じたので、
さくっとCloudFormationで一括デプロイすることにしました。
次の章で手順を紹介します。
2. データエクスポート(CUR 2.0)の作り方【CloudFormation編】
こちらの手順をご紹介する前に、1点注意事項です。
2025年10月時点で作成した時は、データエクスポートをCloudFormationでデプロイするにはリージョンをバージニア北部にする必要がありました。
これはBilling and Cost Management Data Exportsサービスの主なサポートリージョンは 米国東部(バージニア北部、us-east-1) であることが関係しています。
異なるリージョンにデプロイするにはリージョンごとにスタックを分ける必要があります。
今回はデータエクスポートのみをバージニア北部にデプロイし、出力先のS3バケットやレポート確認用のGlueデータベースなどは東京リージョンでデプロイすることにしました。
作成順はS3バケットなどのインフラ系リソース→データエクスポートリソースとします。
デプロイ用Shell(create-cost-usage-report.sh) ※実行前にAWS SSOログイン済みであることを前提としています。
実行方法: create-cost-usage-report.sh --accountname AccountName --bucketname BucketName
for OPT in "$@"
do
case "$OPT" in
'--accountname' )
ACCOUNT_NAME="${2}"
shift 2
;;
'--bucketname' )
BUCKET_NAME="$2"
shift 2
;;
esac
done
# スタック名とレポート名を設定(※各システムに対応できるようにアカウント名を使用)
STACK_NAME_INFRA="${ACCOUNT_NAME}-cost-usage-infra"
STACK_NAME_BCM="${ACCOUNT_NAME}-cost-usage-bcm"
REPORT_NAME="${ACCOUNT_NAME}-cost-usage-report"
echo "東京リージョン(ap-northeast-1)にS3、Glue、IAMリソースを作成中..."
# 1. まず東京リージョンにS3バケット、Glue、IAMリソースを作成
aws cloudformation deploy \
--stack-name ${STACK_NAME_INFRA} \
--template-file ./cfn/create-cur-infra.yml \
--region ap-northeast-1 \
--capabilities CAPABILITY_NAMED_IAM \
--parameter-overrides AccountName=${ACCOUNT_NAME} \
BucketName=${BUCKET_NAME} \
ReportName=${REPORT_NAME} \
--no-fail-on-empty-changeset
# 東京リージョンのデプロイが成功した場合のみ、BCMデータエクスポートを作成
if [ $? -eq 0 ]; then
echo "バージニアリージョン(us-east-1)にBCM Data Exportsを作成中..."
# 2. 次にバージニアリージョンにBCM Data Exportsのみ作成
aws cloudformation deploy \
--stack-name ${STACK_NAME_BCM} \
--template-file ./cfn/create-bcm-data-export.yml \
--region us-east-1 \
--capabilities CAPABILITY_NAMED_IAM \
--parameter-overrides AccountName=${ACCOUNT_NAME} \
BucketName=${BUCKET_NAME} \
ReportName=${REPORT_NAME} \
--no-fail-on-empty-changeset
else
echo "インフラストラクチャスタックの作成に失敗しました。BCM Data Exportsの作成をスキップします。"
exit 1
fi
インフラ作成用テンプレート(create-cur-infra.yml)
AWSTemplateFormatVersion: '2010-09-09'
Description: Full Stack for CUR2.0 with S3 Bucket, Glue Database, and Crawler
#------------------------------------------------------------------------------
Parameters:
#------------------------------------------------------------------------------
AccountName:
Description: "Please input Account name."
Type: "String"
AllowedPattern: "[-a-zA-Z0-9]*"
BucketName:
Type: String
Description: Set the Bucket name.
ReportName:
Description: "Please input report name."
Type: "String"
AllowedPattern: "[-a-zA-Z0-9]*"
# ここで任意の文字列をPrefixのデフォルトに設定
PrefixName:
Type: String
Description: Set the Prefix name.
Default: "cur-data"
#------------------------------------------------------------------------------
Resources:
#------------------------------------------------------------------------------
# 1. CURレポートを出力するためのS3バケット
CURBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Ref BucketName
# 2. CURサービスがS3バケットに書き込むためのバケットポリシー
CURBucketPolicy:
Type: AWS::S3::BucketPolicy
Properties:
Bucket: !Ref CURBucket
PolicyDocument:
Version: '2012-10-17'
Statement:
- Sid: AllowCURWriting
Effect: Allow
Principal:
Service:
- billingreports.amazonaws.com
- bcm-data-exports.amazonaws.com
Action:
- s3:GetBucketAcl
- s3:GetBucketPolicy
- s3:PutObject
Resource:
- !GetAtt CURBucket.Arn
- !Sub '${CURBucket.Arn}/*'
# 3. Glueデータベース
CURGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref 'AWS::AccountId'
DatabaseInput:
Name: !Sub '${AccountName}-cost-report'
Description: 'Database for AWS Cost and Usage Reports.'
# 4. Glue Crawlerサービスロール
CURCrawlerRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub '${AccountName}-cost-report-crawler-role'
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: glue.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
Policies:
- PolicyName: CURCrawlerS3Access
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:GetObject
- s3:ListBucket
Resource:
- !GetAtt CURBucket.Arn
- !Sub '${CURBucket.Arn}/*'
# 5. Glue Crawler
CURCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: !Sub '${ReportName}-crawler'
Description: 'Crawler for AWS Cost and Usage Reports BCM Data Exports'
DatabaseName: !Ref CURGlueDatabase
Role: !GetAtt CURCrawlerRole.Arn
TablePrefix: !Sub 'cost-explorer-'
Targets:
S3Targets:
- Path: !Sub 's3://${BucketName}/${PrefixName}/'
Exclusions: []
RecrawlPolicy:
RecrawlBehavior: CRAWL_EVERYTHING
SchemaChangePolicy:
UpdateBehavior: UPDATE_IN_DATABASE
DeleteBehavior: DEPRECATE_IN_DATABASE
LakeFormationConfiguration:
UseLakeFormationCredentials: false
Configuration: |
{
"Version": 1.0,
"CreatePartitionIndex": true,
"Grouping": {
"TableGroupingPolicy": "CombineCompatibleSchemas"
},
"CrawlerOutput": {
"Partitions": {
"AddOrUpdateBehavior": "InheritFromTable"
},
"Tables": {
"AddOrUpdateBehavior": "MergeNewColumns"
}
}
}
Schedule:
ScheduleExpression: 'cron(0 2 * * ? *)'
#------------------------------------------------------------------------------
Outputs:
#------------------------------------------------------------------------------
BucketName:
Description: 'Name of the S3 bucket created for CUR.'
Value: !Ref CURBucket
GlueDatabaseName:
Description: 'Name of the Glue Database.'
Value: !Ref CURGlueDatabase
CrawlerName:
Description: 'Name of the Glue Crawler.'
Value: !Ref CURCrawler
CrawlerRoleName:
Description: 'Name of the Crawler IAM Role.'
Value: !Ref CURCrawlerRole
次にデータエクスポートのテンプレートですが、
作成前に手動で作成したデータエクスポートを開き、「クエリをプレビュー」で設定値を確認します。

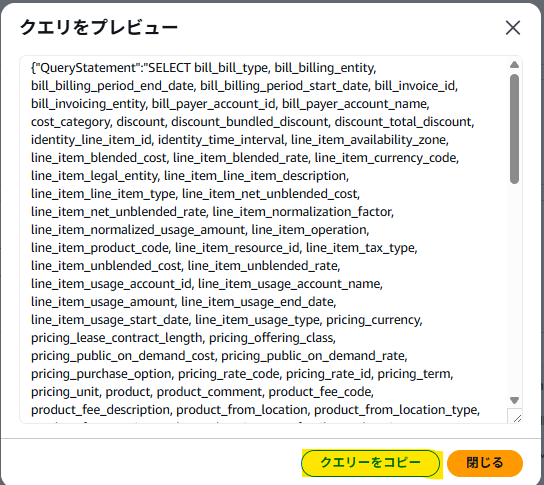
この設定値を参考に、テンプレートを仕上げます。
データエクスポート作成用テンプレート(create-bcm-data-export.yml)
AWSTemplateFormatVersion: '2010-09-09'
Description: BCM Data Export for Cost and Usage Reports
#------------------------------------------------------------------------------
Parameters:
#------------------------------------------------------------------------------
AccountName:
Description: "Please input Account name."
Type: "String"
AllowedPattern: "[-a-zA-Z0-9]*"
BucketName:
Type: String
Description: Set the Bucket name.
ReportName:
Description: "Please input report name."
Type: "String"
AllowedPattern: "[-a-zA-Z0-9]*"
# ここで任意の文字列をPrefixのデフォルトに設定
PrefixName:
Type: String
Description: Set the Prefix name.
Default: "cur-data"
#------------------------------------------------------------------------------
Resources:
#------------------------------------------------------------------------------
# BCM Data Exports標準エクスポート
BCMDataExport:
Type: AWS::BCMDataExports::Export
Properties:
Export:
Name: !Ref ReportName
Description: !Sub "Standard data export for ${AccountName}"
DataQuery:
QueryStatement: "SELECT bill_bill_type, bill_billing_entity, bill_billing_period_end_date, bill_billing_period_start_date, bill_invoice_id, bill_invoicing_entity, bill_payer_account_id, bill_payer_account_name, cost_category, discount, discount_bundled_discount, discount_total_discount, identity_line_item_id, identity_time_interval, line_item_availability_zone, line_item_blended_cost, line_item_blended_rate, line_item_currency_code, line_item_legal_entity, line_item_line_item_description, line_item_line_item_type, line_item_net_unblended_cost, line_item_net_unblended_rate, line_item_normalization_factor, line_item_normalized_usage_amount, line_item_operation, line_item_product_code, line_item_resource_id, line_item_tax_type, line_item_unblended_cost, line_item_unblended_rate, line_item_usage_account_id, line_item_usage_account_name, line_item_usage_amount, line_item_usage_end_date, line_item_usage_start_date, line_item_usage_type, pricing_currency, pricing_lease_contract_length, pricing_offering_class, pricing_public_on_demand_cost, pricing_public_on_demand_rate, pricing_purchase_option, pricing_rate_code, pricing_rate_id, pricing_term, pricing_unit, product, product_comment, product_fee_code, product_fee_description, product_from_location, product_from_location_type, product_from_region_code, product_instance_family, product_instance_type, product_instancesku, product_location, product_location_type, product_operation, product_pricing_unit, product_product_family, product_region_code, product_servicecode, product_sku, product_to_location, product_to_location_type, product_to_region_code, product_usagetype, reservation_amortized_upfront_cost_for_usage, reservation_amortized_upfront_fee_for_billing_period, reservation_availability_zone, reservation_effective_cost, reservation_end_time, reservation_modification_status, reservation_net_amortized_upfront_cost_for_usage, reservation_net_amortized_upfront_fee_for_billing_period, reservation_net_effective_cost, reservation_net_recurring_fee_for_usage, reservation_net_unused_amortized_upfront_fee_for_billing_period, reservation_net_unused_recurring_fee, reservation_net_upfront_value, reservation_normalized_units_per_reservation, reservation_number_of_reservations, reservation_recurring_fee_for_usage, reservation_reservation_a_r_n, reservation_start_time, reservation_subscription_id, reservation_total_reserved_normalized_units, reservation_total_reserved_units, reservation_units_per_reservation, reservation_unused_amortized_upfront_fee_for_billing_period, reservation_unused_normalized_unit_quantity, reservation_unused_quantity, reservation_unused_recurring_fee, reservation_upfront_value, resource_tags, savings_plan_amortized_upfront_commitment_for_billing_period, savings_plan_end_time, savings_plan_instance_type_family, savings_plan_net_amortized_upfront_commitment_for_billing_period, savings_plan_net_recurring_commitment_for_billing_period, savings_plan_net_savings_plan_effective_cost, savings_plan_offering_type, savings_plan_payment_option, savings_plan_purchase_term, savings_plan_recurring_commitment_for_billing_period, savings_plan_region, savings_plan_savings_plan_a_r_n, savings_plan_savings_plan_effective_cost, savings_plan_savings_plan_rate, savings_plan_start_time, savings_plan_total_commitment_to_date, savings_plan_used_commitment FROM COST_AND_USAGE_REPORT"
TableConfigurations:
COST_AND_USAGE_REPORT:
INCLUDE_MANUAL_DISCOUNT_COMPATIBILITY: "FALSE"
INCLUDE_RESOURCES: "TRUE"
INCLUDE_SPLIT_COST_ALLOCATION_DATA: "FALSE"
TIME_GRANULARITY: "DAILY"
DestinationConfigurations:
S3Destination:
S3Bucket: !Ref BucketName
S3Prefix: !Ref PrefixName
S3Region: !Ref AWS::Region
S3OutputConfigurations:
OutputType: "CUSTOM"
Format: "PARQUET"
Compression: "PARQUET"
Overwrite: "OVERWRITE_REPORT"
RefreshCadence:
Frequency: "SYNCHRONOUS"
#------------------------------------------------------------------------------
Outputs:
#------------------------------------------------------------------------------
BCMDataExportArn:
Description: 'ARN of the BCM Data Export.'
Value: !GetAtt BCMDataExport.ExportArn
BCMDataExportName:
Description: 'Name of the BCM Data Export.'
Value: !Ref BCMDataExport
AWSにログインしてからShellを実行します。
accountname=test-account
/bin/bash create-cost-usage-report.sh --accountname ${accountname} --bucketname ${accountname}-cost-usage-report
実行結果:
ACCOUNT_ID: "123456789123" 東京リージョン(ap-northeast-1)にS3、Glue、IAMリソースを作成中... Waiting for changeset to be created.. Waiting for stack create/update to complete Successfully created/updated stack - test-account-cost-usage-infra バージニアリージョン(us-east-1)にBCM Data Exportsを作成中... Waiting for changeset to be created.. Waiting for stack create/update to complete Successfully created/updated stack - test-account-cost-usage-bcm
CloudFormationのスタックはそれぞれのリージョンに作成されます。

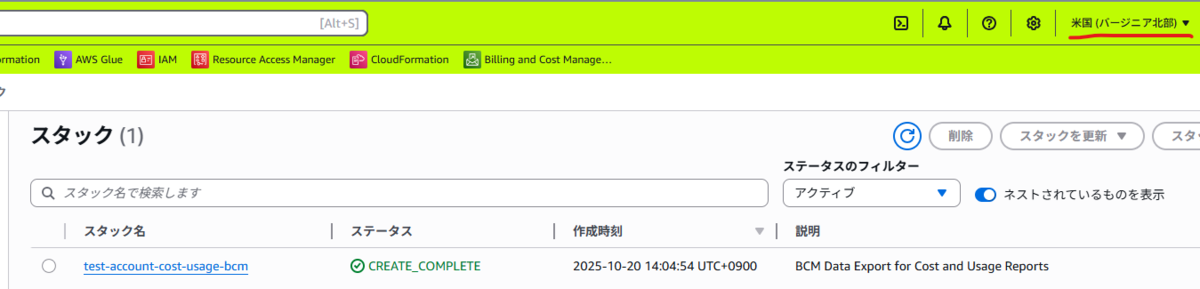
データエクスポートも作成されていますが、手動作成の時と同様に最大24時間待つ必要があります。


こちらも翌日になってからデータの出力を確認することができました。

Crawlersのスケジュール実行も成功していることを確認できました。(2:00 AM UTC = 11:00 AM JST)
 ※今回は初回レポート作成が24時間程度かかることから、ちょうど終わりそうな午前11時を設定していますが、深夜や早朝更新にしておくと朝一から新しいデータを確認できるので便利ですね。
※今回は初回レポート作成が24時間程度かかることから、ちょうど終わりそうな午前11時を設定していますが、深夜や早朝更新にしておくと朝一から新しいデータを確認できるので便利ですね。
Athenaでのデータ参照もできました!
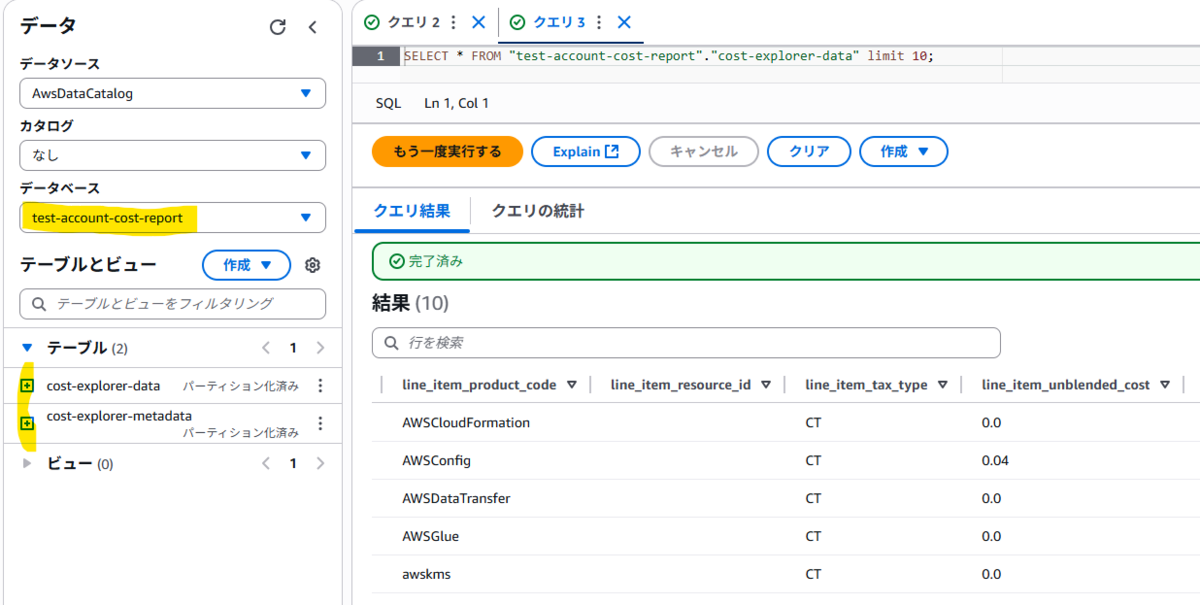
3. Athenaで参照する際の注意事項
レポートが出力され、Athenaでクエリできるようになったところで、いくつか注意事項があるなと思いました。
皆さんが同じ道で迷わないよう、ここで共有します。
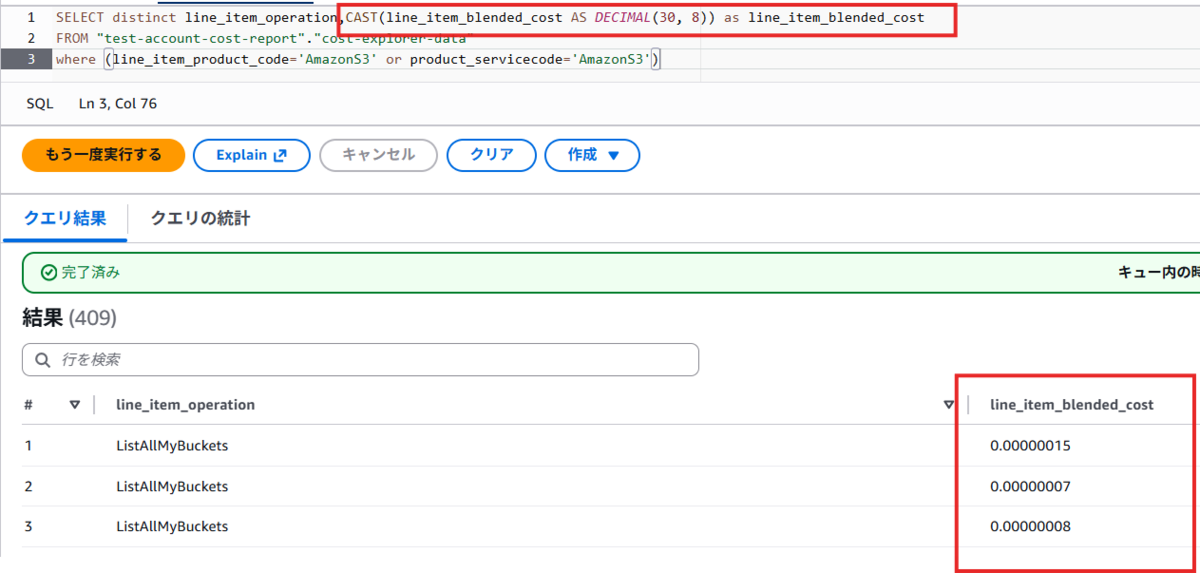
注意事項①:コストや使用量が"2.38E-8"になるのでCASTせよ
Athenaで意気揚々とSELECTして喜んだのも束の間、コスト(line_item_blended_cost) や使用量 (line_item_usage_amount) のカラムが「指数表記(E表記)」になっていることに気づきました。
(たまに見るやつ~!)
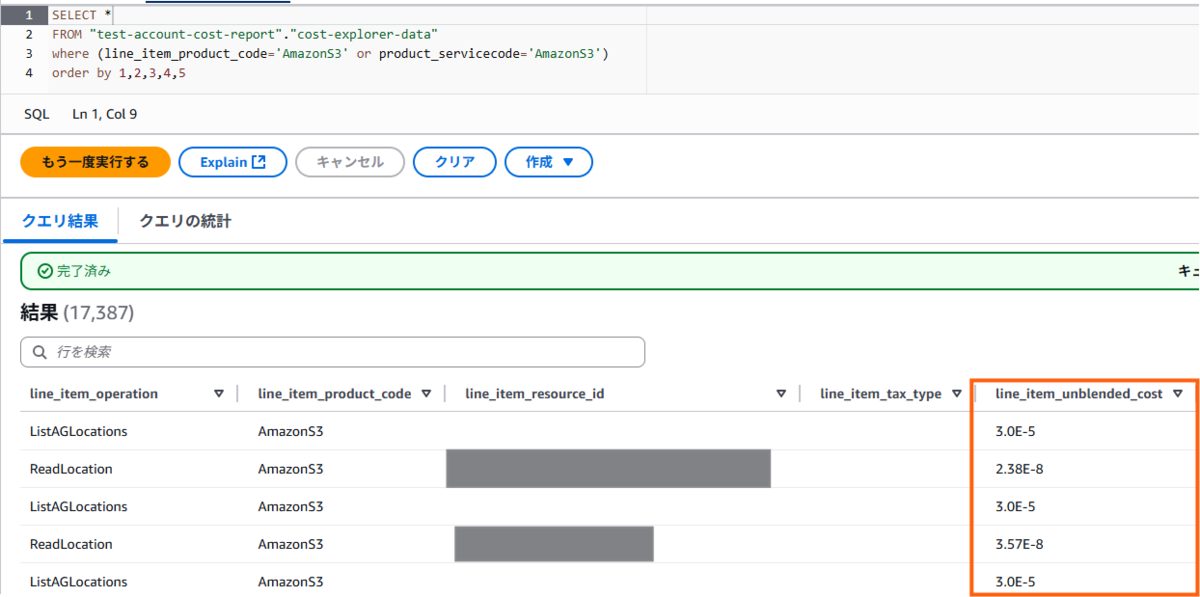
これは、金額項目がdouble型で定義されるために発生しています。
docs.aws.amazon.com
【解決策】
DECIMAL型にCAST(型変換)してから集計します。
CloudFormationでスキーマを事前定義した場合はこの手順は不要ですが、クローラー任せにした場合は必須のテクニックです。
--SQL SELECT distinct line_item_operation,CAST(line_item_blended_cost AS DECIMAL(30, 8)) as line_item_blended_cost FROM "test-account-cost-report"."cost-explorer-data" where (line_item_product_code='AmazonS3' or product_servicecode='AmazonS3')
注意事項②:line_item_resource_idがNULL (空白) の行に驚くことなかれ
コストをリソースごと(バケットごと)に見たいのに、肝心のline_item_resource_idがNULL(空白)の行が大量にあり、非常に悩みました。
【結論】
これは主にAWSのAPI呼び出し(List操作やRead操作)の場合に発生します。
リソース単位ではなくAPI操作単位で課金されるため、line_item_resource_idが空白の状態になるということです。

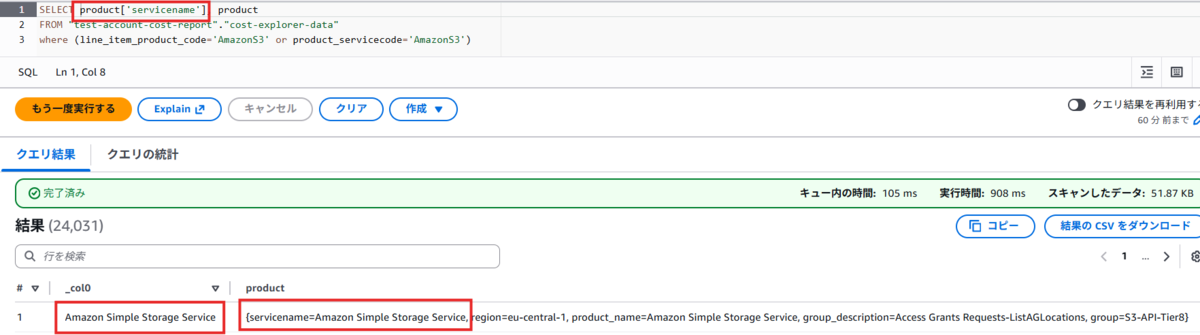
注意事項③:Map形式の項目の扱いに注意せよ
Map型の値は参照するだけなら、項目名を指定すればそのまま値を参照できます。
ですが、以下のように属性名を指定すると属性名の値をピンポイントで表示することができます。
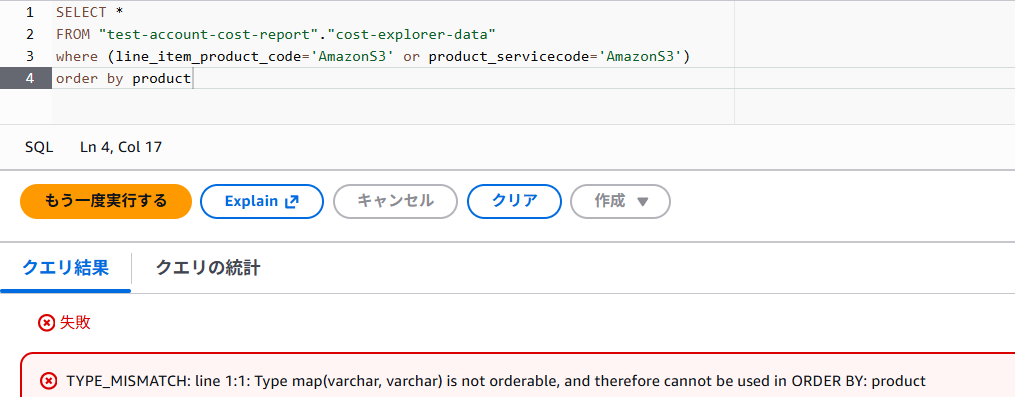
 WHERE句やOREDER BY句で使用する時は属性名まで指定しないとエラーになるので、注意してください。
WHERE句やOREDER BY句で使用する時は属性名まで指定しないとエラーになるので、注意してください。
4. データエクスポート活用法
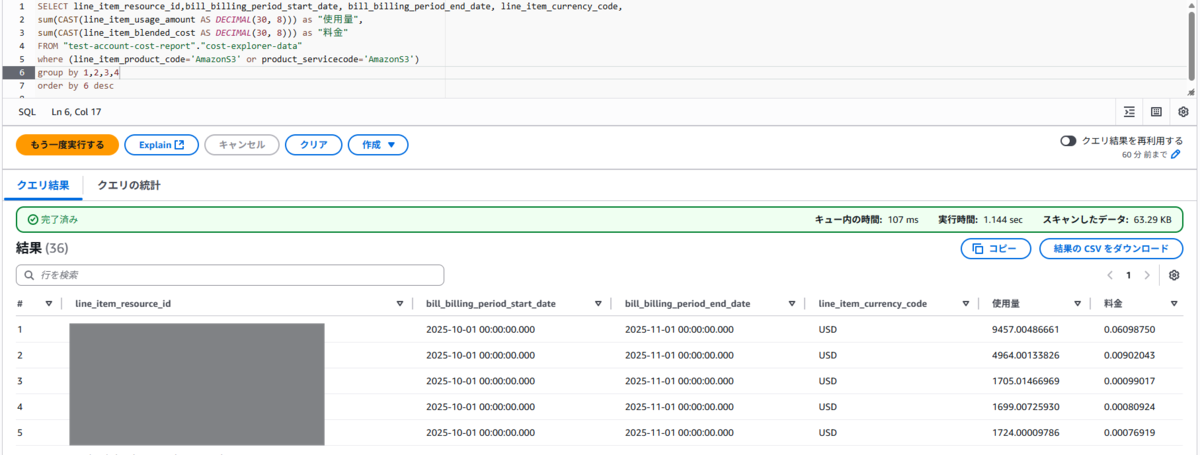
活用法①:コストが高いS3バケットを特定する
--SQL SELECT line_item_resource_id,bill_billing_period_start_date, bill_billing_period_end_date, line_item_currency_code, sum(CAST(line_item_usage_amount AS DECIMAL(30, 8))) as "使用量", sum(CAST(line_item_blended_cost AS DECIMAL(30, 8))) as "料金" FROM "test-account-cost-report"."cost-explorer-data" where (line_item_product_code='AmazonS3' or product_servicecode='AmazonS3') group by 1,2,3,4 order by 6 desc
今回使った環境は会社の学習用アカウントなので金額が少なめですが、1番高い料金から並べて表示することができています。
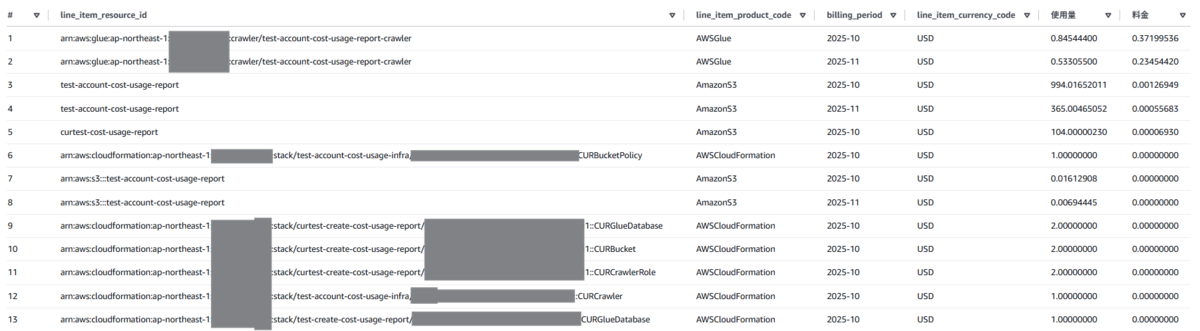
活用法②:リソースを特定して分析する
今回作成したコストレポート関連のリソースの料金を確認してみたいと思います。
--SQL SELECT line_item_resource_id, line_item_product_code, billing_period, line_item_currency_code, sum(CAST(line_item_usage_amount AS DECIMAL(30, 8))) as "使用量", sum(CAST(line_item_blended_cost AS DECIMAL(30, 8))) as "料金" FROM "test-account-cost-report"."cost-explorer-data" where line_item_resource_id like '%cost%' group by 1,2,3,4 order by 6 desc
CloudFormationのスタックは料金がかからないものの、コストとしては登録されているようですね。
billing_periodを使用して月別の金額も出せています。
5. 最後に
ここまで、データエクスポートを作成し、Athenaでクエリしてコストを確認するまでの一連の流れを紹介しました。
この分析基盤を使えば、AthenaでSQLを実行するだけで、
Cost Explorerでは追いきれなかったS3バケットごとの料金や、
特定のAPI操作(GetObjectやPutObjectなど)にいくらかかっているかを正確に把握できます。
必要な時にAthenaでSQLを直接実行できるようになったことで、
「リソース単位でのコスト内訳を詳細に把握し、異常を検知する」ことができるようになりました。
より日常的・定点的に検知する必要がある場合は、このAthenaテーブルをAmazon QuickSightなどのBIツールに接続するのも面白そうです。
Cost Explorerでは物足りなくなってきた方にとって、 この記事が「詳細なコスト分析」への最初の一歩として参考になれば幸いです!!
明日5日目は、八杉さんによる「アイコンのデフォルトサイズを 1em から 1lh にする」です。
JMDCでは、ヘルスケア領域の課題解決に一緒に取り組んでいただける方を積極採用中です! フロントエンド /バックエンド/ データベースエンジニア等、様々なポジションで募集をしています。 詳細は下記の募集一覧からご確認ください。 hrmos.co
まずはカジュアルにJMDCメンバーと話してみたい/経験が活かせそうなポジションの話を聞いてみたい等ございましたら、下記よりエントリーいただけますと幸いです。 hrmos.co
★最新記事のお知らせはぜひ X(Twitter)、またはBlueskyをご覧ください! Tweets by jmdc_tech twitter.com bsky.app
